
해시(Hash) 자료구조
해시(Hash) 구조란, 키(Key)와 값(Value) 쌍으로 이루어진 데이터 구조입니다. 해시 구조에서는 Key 를 이용하여 데이터(value)를 빠르게 찾을 수 있는 장점이 있습니다.
파이썬에서 사용하는 dictionary type 이 해시구조입니다.
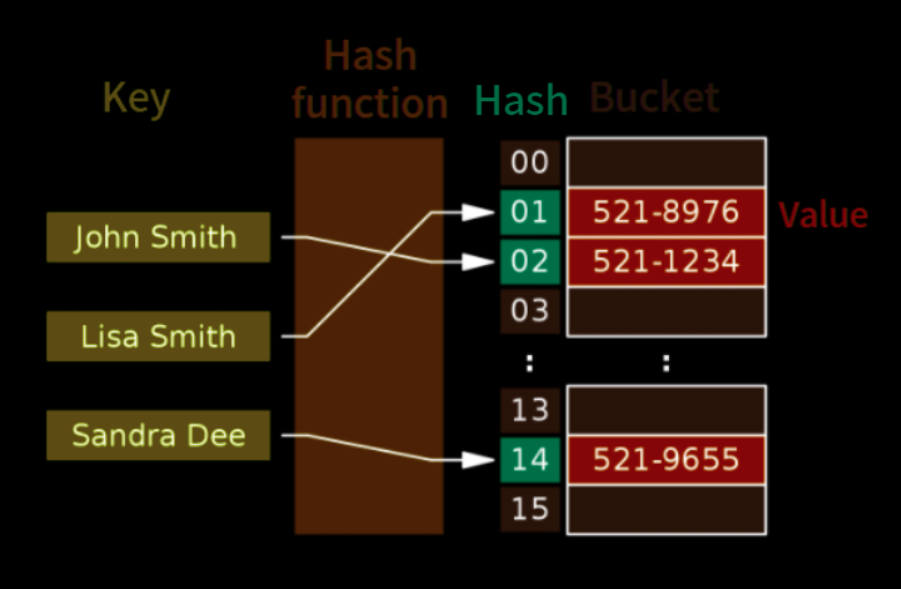
해시와 관련된 몇가지 용어들에 대해 알아보겠습니다.
- 키 (Key) : 해시 함수의 input 이 되는 고유한 값.
키(key)는 해시함수(hash function)를 통해 해시(hash)로 변경되어 value 값과 매칭되어 저장소에 저장됩니다.
- 해시 (Hash) : 임의의 값을 고정 길이로 변환하는 것
key 값 그대로 저장소에 저장되게 되면 다양한 길이의 저장소를 구성해야하기 때문에 효율성을 위해 일관적으로 해시(hash)로 변경하여 저장함으로써 공간 효율성을 최적화합니다.
- 해시 테이블 (Hash Table) : Key 값의 연산에 의해 직접 접근이 가능한 데이터 구조
- 버킷 (Bucket), 슬롯 (Slot) : Hash table 에서 하나의 데이터가 저장되는 공간
- 해시 함수 (Hashing Function) : Key 값에 대해 연산을 통해 데이터(value) 위치를 찾는 함수
- Hash Value, Hask Address : Key 값을 이용해 Hashing function 을 연산하여 Value 를 알아낼 수 있고, 이를 기반으로 Hash table 에서 해당 key 에 대한 데이터 위치(주소)를 찾을 수 있음
파이썬에서는 dictionary 형태로 이러한 해시 자료구조가 구현되어 있습니다.
my_dict = {'name' : 'Jayden', 'phone_num' : '010-123-4567', 'heiht' : 180, 'weight' : 80}
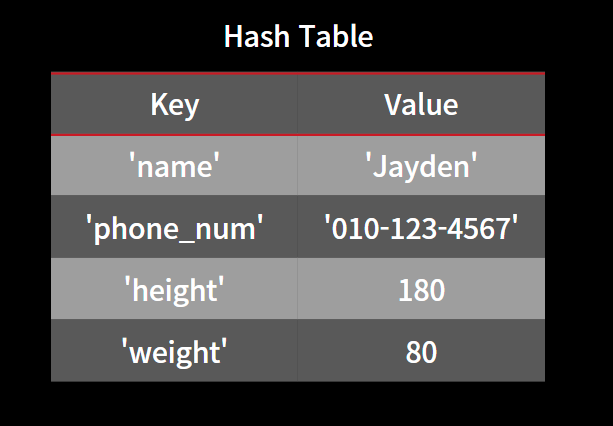
Hash Table 기능
기본적으로 Hash table 은 몇가지 기본 기능을 제공합니다.
- 데이터 삽입(저장)
Hash table 에서 데이터를 저장하기 위해서는 먼저 hach function 을 이용하여 key 값을 hash 로 변경합니다.
이후 미리 준비해둔 저장소(bucket, slot) 중에 알맞는 hash 값을 찾아 value 를 저장합니다.
따라서 이러한 데이터 삽입(저장) 과정의 시간복잡도는 입니다.
해시 충돌이 일어나지 않는다는 가정하에
해시 충돌에 대한 설명은 아래에 있습니다.
- 데이터 삭제
저장되어 있는 값을 삭제가기 위해서는 bucket 에서 삭제하려고하는 key 와 매칭되는 value 값을 찾아서 삭제합니다.
따라서 이러한 데이터 삭제 과정의 시간복잡도는 입니다.
해시 충돌이 일어나지 않는다는 가정하에
- 데이터 검색
key 를 이용해 value 를 찾아내는 과정입니다. 먼저 key값과 hash function 을 이용해 hash 를 찾아내고 해당 hash 로 value 값을 찾을 수 있습니다.
이러한 데이터 검색 과정의 시간복잡도는 입니다. 해시 충돌이 일어나지 않는다는 가정하에
hash table 은 위의 기본 기능들이 가능하고 모든 각각의 기능들의 시간복잡도는 로 아주 효율적인 것을 알 수 있습니다.
따라서 hash table 은 데이터 저장, 삭제, 검색이 많이 필요한 경우에 자주 사용됩니다.
하지만 hash table의 단점 도 존재합니다.
먼저 hash 값들을 저장할 공간(bucket)을 지정해야하므로 일반적으로 저장 공간이 많이 필요 합니다.
또한 여러 key 에 해당하는 hash(주소)가 동일한 경우 해시 충돌 (Hash Collision) 이 발생합니다.
해시 충돌(Hash Collision)
위의서 hash table 의 단점으로 언급했던 여러 key 에 해당하는 hash(주소)가 동일한 경우를 해시 충돌(Hash Collision)이라고 부릅니다.
비둘기집의 원리로 인해 hash 를 이용한 자료구조에서는 무조전적으로 일어날 수 밖에 없는 현상입니다.
cf) 비둘기집원리: n+1개의 물건을 n개의 상자에 넣은 경우, 최소한 한 상자에는 그 물건이 반드시 두 개 이상 들어있다는 원리
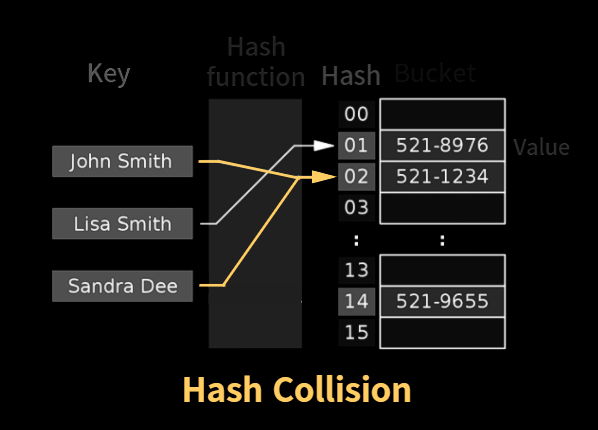
이러한 충돌 문제를 해결하기 위한 여러 가지 방법들에 대해 알아보겠습니다.
Chaning (Open Hashing)
먼저 연결리스트(linked list) 를 이용하는 방법인 Chaning 방법을 이용해 해시 충돌 문제를 해결할 수 있습니다.
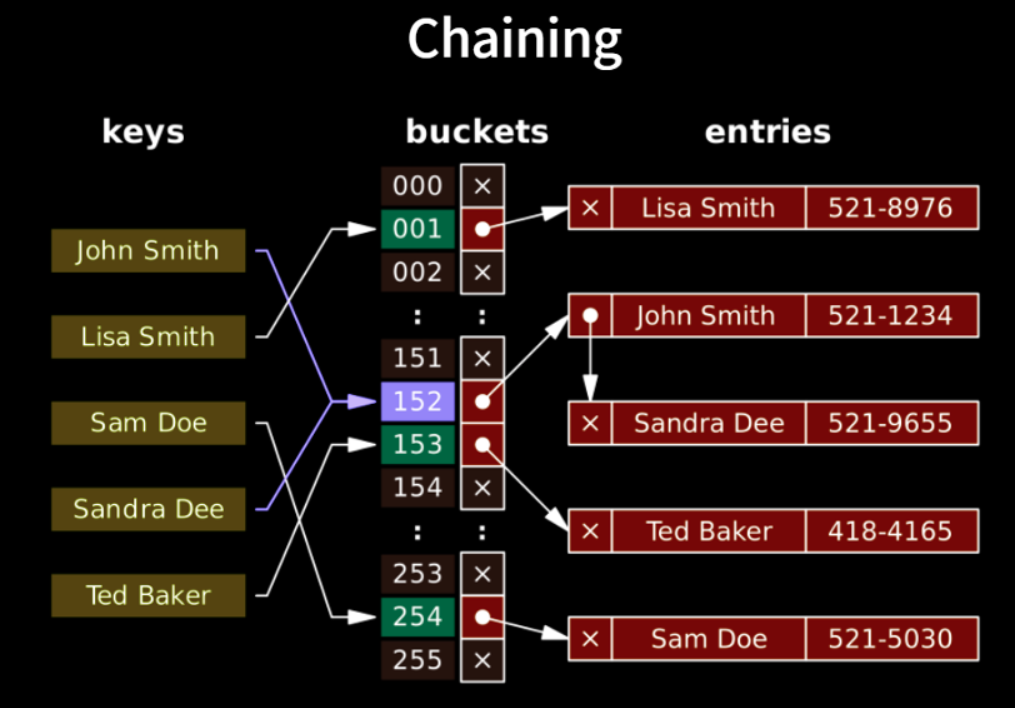
Chaining 방법은 해시 충돌이 발생했을 때 이를 동일한 bucket에 저장 하되 나중에 저장되는 값을 연결리스트 형태로 저장하는 방법입니다.
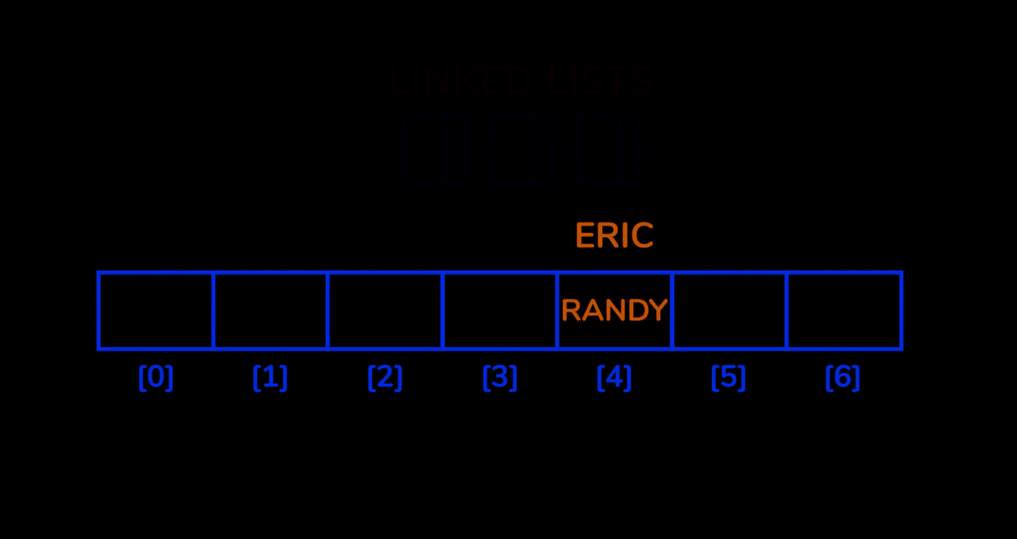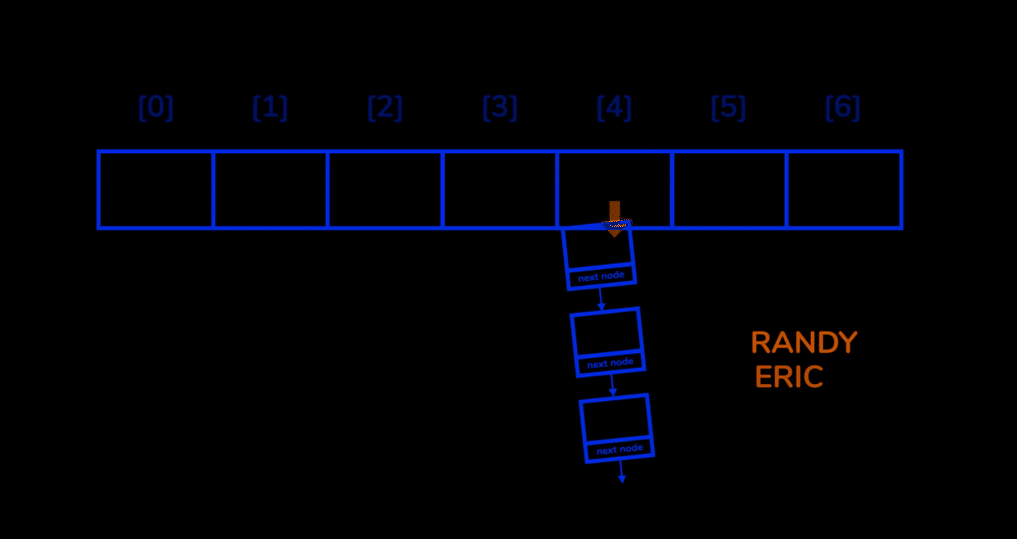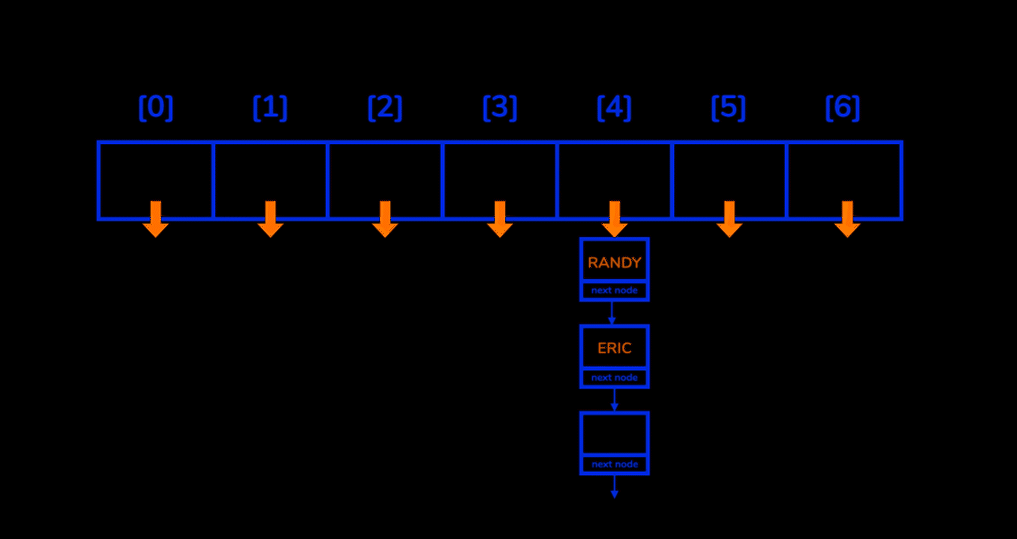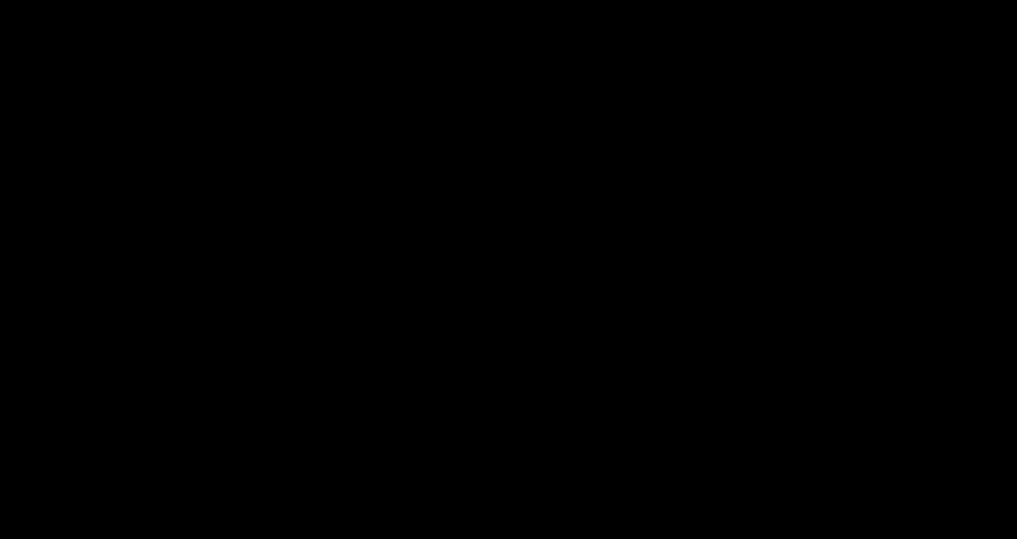
Chaining 을 통해 hash table 을 생성하였을때 기능들의 시간복잡도는 까지 늘어날 수도 있다는 단점이 있습니다.
linked list 의 요소들을 처음부터 하나씩 찾아야하므로
Open Addressing (Close hashing)
다음으로 해시 충돌을 해결할 수 있는 방법으로 Open Addressing 방법이 있습니다.
Close hashing, Linear probing 이라고 부르기도 합니다.
Open Addressing 방법은 해시 충돌이 일어날 경우, 비어있는 hash를 찾아 데이터를 저장하는 기법입니다.
따라서 Chaining 방법에서는 하나의 hash 에 여러 value 들이 저장되었던 반면, Open addressing 에서는 무조건적으로 1개의 해시와 1개의 value 만이 매칭되게 됩니다.
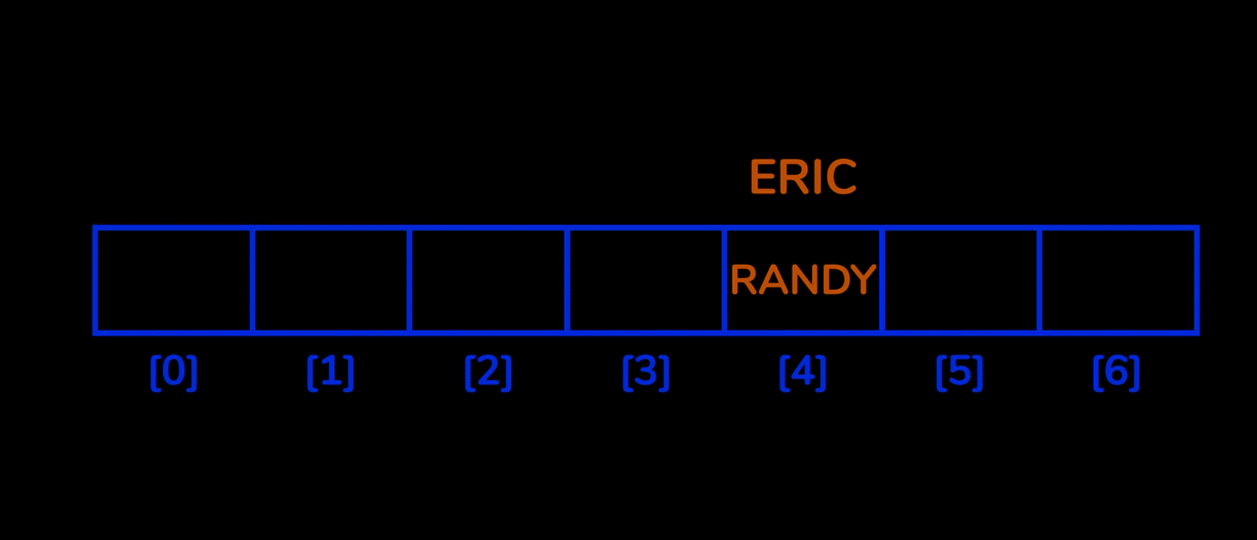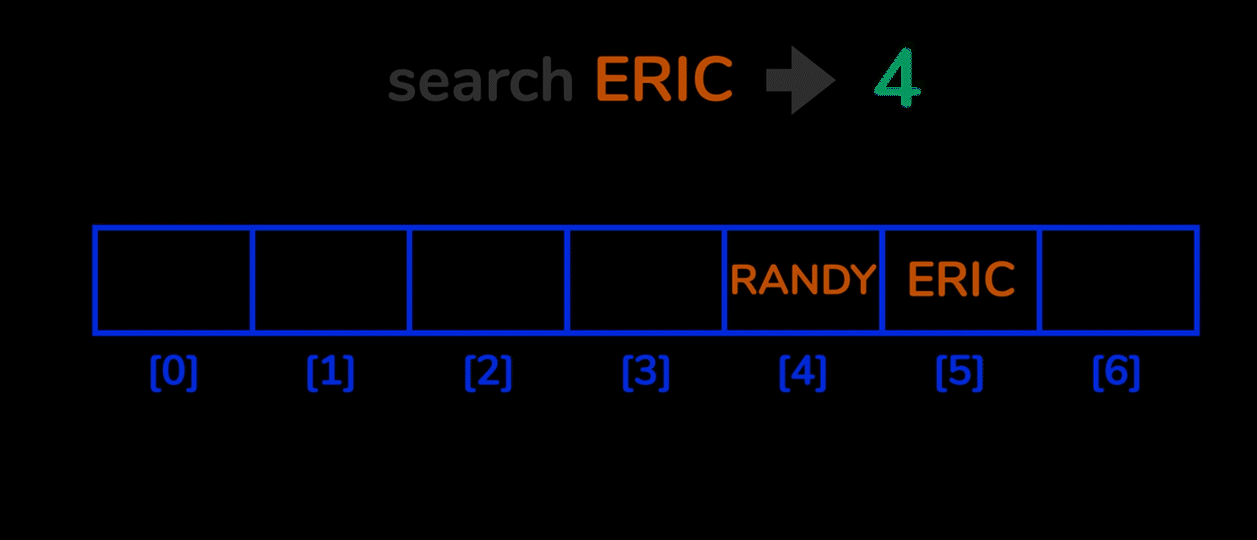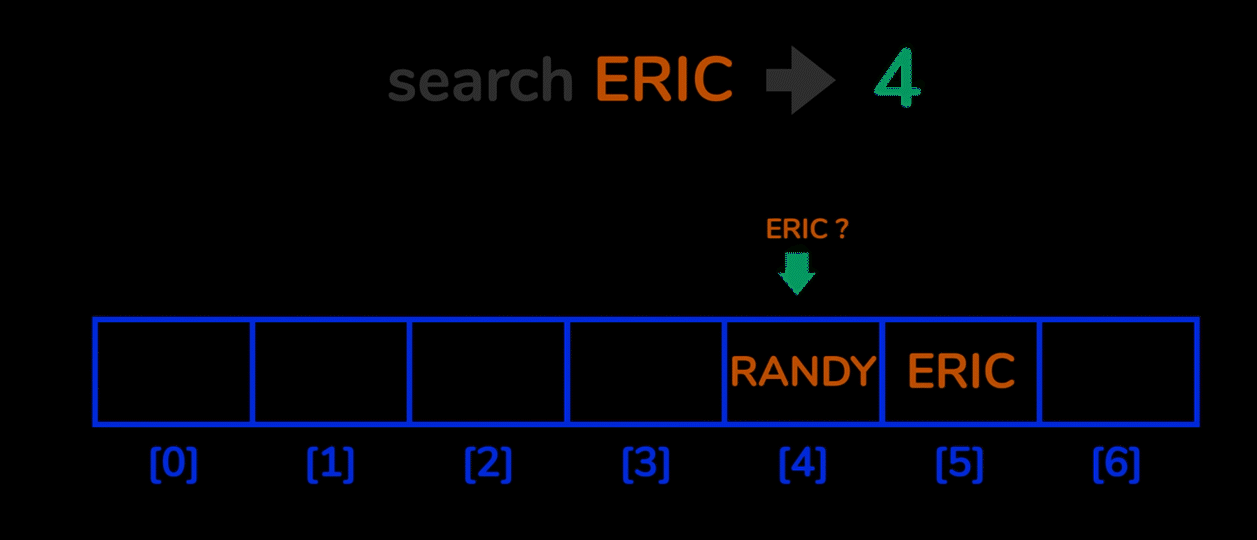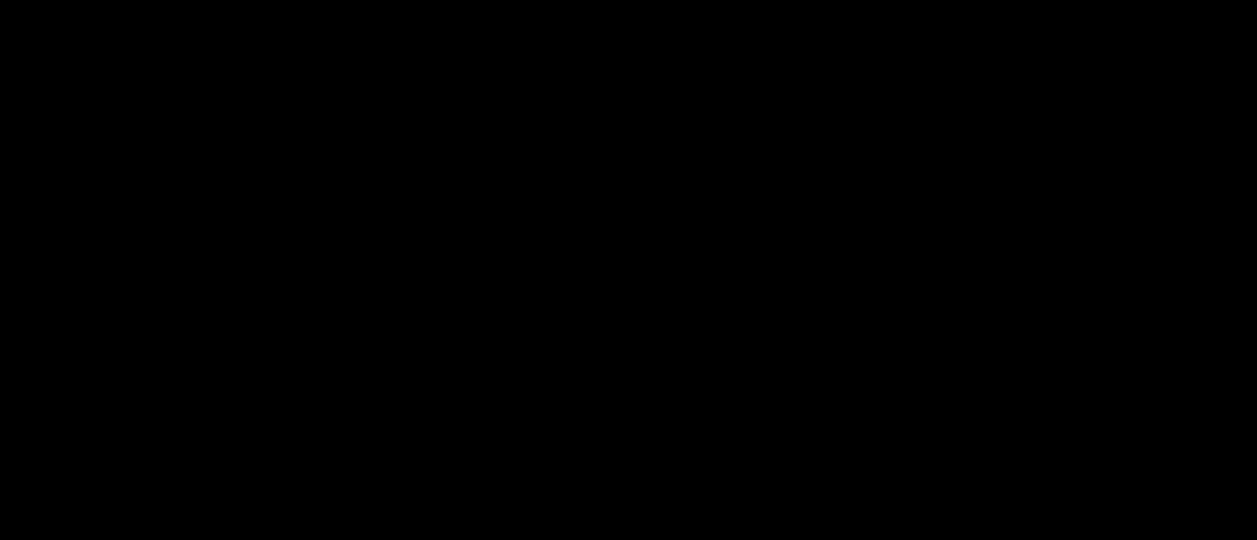
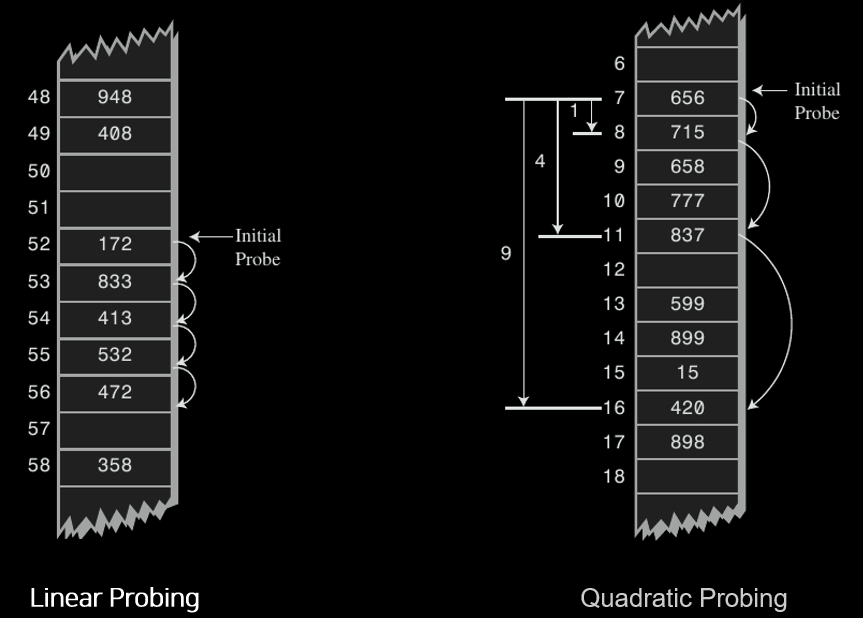
이때, 비어있는 hash 를 찾는 방법으로 단순히 한칸씩 옆으로 옮기며 빈 공간(bucket) 를 찾아가는 linear probing 방법이 있습니다.
이러한 linear probing 방법을 사용하면 데이터들이 특정 위치에만 밀집하는 clustering 문제가 발생할 수 있습니다.
이 문제를 해결하기위해 을 건너뛰어 빈 공간(bucket) 를 찾아가는 quadratic probing 방법도 있습니다.
파이썬으로 Hash 구현
파이썬을 이용하여 Hash 데이터 구조와 여러 기능을 간단히 구현할 수 있습니다.
먼저, hash table 을 파이썬 리스트를 이용하여 아래와 같이 구현할 수 있습니다.
class HashTable:
def __init__(self, table_size):
self.size = table_size # 총 공간(bucket) 수
self.hash_table = [0 for a in range(self.size)] # 빈 hash table 생성
def getKey(self, data): # key(문자) 첫 문자의 유니코드를 반환
self.key = ord(data[0])
return self.key
def hashFunction(self, key): # key 의 hash 값을 반환
return key % self.size
def getAddress(self, key): # hash address 를 반환
myKey = self.getKey(key)
hash_address = self.hashFunction(myKey)
return hash_address
def save(self, key, value): # 데이터 저장
hash_address = self.getAddress(key)
self.hash_table[hash_address] = value
def read(self, key): # key 에 해당하는 value 반환
hash_address = self.getAddress(key)
return self.hash_table[hash_address]
def delete(self, key): # 데이터 삭제
hash_address = self.getAddress(key)
if self.hash_table[hash_address] != 0:
self.hash_table[hash_address] = 0
return True
else:
return False
if __name__ == '__main__':
h_table = HashTable(8)
h_table.save('a', '1111')
h_table.save('b', '2222')
h_table.save('c', '3333')
h_table.save('d', '4444')
print(h_table.hash_table) # [0, '1111', '2222', '3333', '4444', 0, 0, 0]
print(h_table.read('d')) # 4444
h_table.delete('d')
print(h_table.hash_table) # [0, '1111', '2222', 0, '4444', 0, 0, 0]
다음으로 hash table 문제를 해결할 수 있는 방법 중 Chaining 방법을 구현해보겠습니다.
이론상으로 chaining 방법은 linked list 를 사용하여 구현할 수 있지만 파이썬에서는 이중리스트를 이용하여 더욱 간결하게 구현할 수 있습니다.
class Chaining:
def __init__(self, table_size):
self.size = table_size
self.hash_table = [0 for a in range(self.size)]
def getKey(self, data):
self.key = ord(data[0])
return self.key
def hashFunction(self, key):
return key % self.size
def getAddress(self, key):
myKey = self.getKey(key)
hash_address = self.hashFunction(myKey)
return hash_address
def save(self, key, value):
hash_address = self.getAddress(key)
if self.hash_table[hash_address] != 0: # 해시 충돌 시
for a in range(len(self.hash_table[hash_address])): # 빈 bucket 탐색
if self.hash_table[hash_address][a][0] == key: # key 에 맞는 value 매칭
self.hash_table[hash_address][a][1] = value
return
self.hash_table[hash_address].append([key, value])
else:
self.hash_table[hash_address] = [[key, value]]
def read(self, key):
hash_address = self.getAddress(key)
if self.hash_table[hash_address] != 0: # 해시 충돌 시
for a in range(len(self.hash_table[hash_address])):
if self.hash_table[hash_address][a][0] == key: # 일치하는 key 값 찾음
return self.hash_table[hash_address][a][1] # 일치하는 value 반환
return False
else:
return False
def delete(self, key):
hash_address = self.getAddress(key)
if self.hash_table[hash_address] != 0:
for a in range(len(self.hash_table[hash_address])):
if self.hash_table[hash_address][a][0] == key:
if len(self.hash_table[hash_address]) == 1:
self.hash_table[hash_address] = 0
else:
del self.hash_table[hash_address][a]
return
return False
else:
return False
if __name__ == '__main__':
h_table = Chaining(8)
h_table.save('aa', '1111')
print(h_table.read('aa')) # 1111
data1 = 'aa'
data2 = 'ab'
print(ord(data1[0])) # 97
print(ord(data2[0])) # 97 같은 hash 값을 가짐 -> 해시 충돌
h_table.save('ab', '2222')
print(h_table.hash_table) # [0, [['aa', '1111'], ['ab', '2222']], 0, 0, 0, 0, 0, 0]
print(h_table.read('aa')) # 1111
print(h_table.read('ab')) # 2222
h_table.delete('aa')
print(h_table.hash_table) # [0, [['ab', '2222']], 0, 0, 0, 0, 0, 0]
print(h_table.delete('Data')) # False
이어서 해시 충돌을 해결할 수 있는 방법 중 하나인 Open Addressing 방법을 파이썬으로 구현해보겠습니다.
class OpenAddressing:
def __init__(self, table_size):
self.size = table_size
self.hash_table = [0 for a in range(self.size)]
def getKey(self, data):
self.key = ord(data[0])
return self.key
def hashFunction(self, key):
return key % self.size
def getAddress(self, key):
myKey = self.getKey(key)
hash_address = self.hashFunction(myKey)
return hash_address
def save(self, key, value):
hash_address = self.getAddress(key)
if self.hash_table[hash_address] != 0: # hash 의 값이 이미 존재할때 (해시충돌)
for a in range(hash_address, len(self.hash_table)):
if self.hash_table[a] == 0:
self.hash_table[a] = [key, value]
return
elif self.hash_table[a][0] == key:
self.hash_table[a] = [key, value]
return
return None
else: # hash 가 비었을때
self.hash_table[hash_address] = [key, value]
def read(self, key):
hash_address = self.getAddress(key)
for a in range(hash_address, len(self.hash_table)):
if self.hash_table[a][0] == key:
return self.hash_table[a][1]
return None
def delete(self, key):
hash_address = self.getAddress(key)
for a in range(hash_address, len(self.hash_table)):
if self.hash_table[a] == 0:
continue
if self.hash_table[a][0] == key:
self.hash_table[a] = 0
return
return False
if __name__=='__main__':
h_table = OpenAddresing(8)
data1 = 'aa'
data2 = 'ab'
print(ord(data1[0]), ord(data2[0])) ## 97 97 -> 해시 충돌
h_table.save('aa', '1111')
h_table.save('ab', '2222')
print(h_table.hash_table) # [0, ['aa', '1111'], ['ab', '2222'], 0, 0, 0, 0, 0]
print(h_table.read('ab')) # 2222
h_table.delete('aa')
print(h_table.hash_table) # [0, 0, ['ab', '2222'], 0, 0, 0, 0, 0]
[ Java의 HashMap(해시맵) vs HashTable(해시테이블) ]
Java 개발자라면 (Key,Value)로 저장하는 익숙한 자료구조인 HashMap이 있다. 그렇다면 Java에서 HashTable과 HashMap의 차이가 당연히 있을 텐데, 그 차이는 동기화 지원 여부에 있다.
// 해시테이블의 put
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
// 해시맵의 put
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}위의 코드에서 첫번째 put은 해시테이블의 put이며, 두번째 put은 해시맵의 put이다. 첫번째 해시테이블의 put에는 synchronized 키워드가 붙어있는 것을 확인할 수 있는데, 이것은 병렬 프로그래밍을 할 때 동기화를 지원해준다는 것을 의미한다. 이것은 해당 함수를 처리하는 시간이 조금 지연됨을 의미힌다.
그렇기 때문에 우리는 병렬 처리를 하면서 자원의 동기화를 고려해야 하는 상황이라면 해시테이블(HashTable)을 사용해야 하며, 병렬 처리를 하지 않거나 자원의 동기화를 고려하지 않는 상황이라면 해시맵(HashMap)을 사용하면 된다.
원글 출처:https://ai-rtistic.com/2022/01/29/data-structure-hash/
해시(Hash) 자료구조
해시(Hash) 구조란, 키(Key)와 값(Value) 쌍으로 이루어진 데이터 구조입니다. 해시 구조에서는 Key 를 이용하여 데이터(value)를 빠르게 찾을 수 있는 장점이 있습니다.
파이썬에서 사용하는 dictionary type 이 해시구조입니다.
해시와 관련된 몇가지 용어들에 대해 알아보겠습니다.
- 키 (Key) : 해시 함수의 input 이 되는 고유한 값.
키(key)는 해시함수(hash function)를 통해 해시(hash)로 변경되어 value 값과 매칭되어 저장소에 저장됩니다.
- 해시 (Hash) : 임의의 값을 고정 길이로 변환하는 것
key 값 그대로 저장소에 저장되게 되면 다양한 길이의 저장소를 구성해야하기 때문에 효율성을 위해 일관적으로 해시(hash)로 변경하여 저장함으로써 공간 효율성을 최적화합니다.
- 해시 테이블 (Hash Table) : Key 값의 연산에 의해 직접 접근이 가능한 데이터 구조
- 버킷 (Bucket), 슬롯 (Slot) : Hash table 에서 하나의 데이터가 저장되는 공간
- 해시 함수 (Hashing Function) : Key 값에 대해 연산을 통해 데이터(value) 위치를 찾는 함수
- Hash Value, Hask Address : Key 값을 이용해 Hashing function 을 연산하여 Value 를 알아낼 수 있고, 이를 기반으로 Hash table 에서 해당 key 에 대한 데이터 위치(주소)를 찾을 수 있음
파이썬에서는 dictionary 형태로 이러한 해시 자료구조가 구현되어 있습니다.
my_dict = {'name' : 'Jayden', 'phone_num' : '010-123-4567', 'heiht' : 180, 'weight' : 80}
Hash Table 기능
기본적으로 Hash table 은 몇가지 기본 기능을 제공합니다.
- 데이터 삽입(저장)
Hash table 에서 데이터를 저장하기 위해서는 먼저 hach function 을 이용하여 key 값을 hash 로 변경합니다.
이후 미리 준비해둔 저장소(bucket, slot) 중에 알맞는 hash 값을 찾아 value 를 저장합니다.
따라서 이러한 데이터 삽입(저장) 과정의 시간복잡도는 입니다.
해시 충돌이 일어나지 않는다는 가정하에
해시 충돌에 대한 설명은 아래에 있습니다.
- 데이터 삭제
저장되어 있는 값을 삭제가기 위해서는 bucket 에서 삭제하려고하는 key 와 매칭되는 value 값을 찾아서 삭제합니다.
따라서 이러한 데이터 삭제 과정의 시간복잡도는 입니다.
해시 충돌이 일어나지 않는다는 가정하에
- 데이터 검색
key 를 이용해 value 를 찾아내는 과정입니다. 먼저 key값과 hash function 을 이용해 hash 를 찾아내고 해당 hash 로 value 값을 찾을 수 있습니다.
이러한 데이터 검색 과정의 시간복잡도는 입니다. 해시 충돌이 일어나지 않는다는 가정하에
hash table 은 위의 기본 기능들이 가능하고 모든 각각의 기능들의 시간복잡도는 로 아주 효율적인 것을 알 수 있습니다.
따라서 hash table 은 데이터 저장, 삭제, 검색이 많이 필요한 경우에 자주 사용됩니다.
하지만 hash table의 단점 도 존재합니다.
먼저 hash 값들을 저장할 공간(bucket)을 지정해야하므로 일반적으로 저장 공간이 많이 필요 합니다.
또한 여러 key 에 해당하는 hash(주소)가 동일한 경우 해시 충돌 (Hash Collision) 이 발생합니다.
해시 충돌(Hash Collision)
위의서 hash table 의 단점으로 언급했던 여러 key 에 해당하는 hash(주소)가 동일한 경우를 해시 충돌(Hash Collision)이라고 부릅니다.
비둘기집의 원리로 인해 hash 를 이용한 자료구조에서는 무조전적으로 일어날 수 밖에 없는 현상입니다.
cf) 비둘기집원리: n+1개의 물건을 n개의 상자에 넣은 경우, 최소한 한 상자에는 그 물건이 반드시 두 개 이상 들어있다는 원리
이러한 충돌 문제를 해결하기 위한 여러 가지 방법들에 대해 알아보겠습니다.
Chaning (Open Hashing)
먼저 연결리스트(linked list) 를 이용하는 방법인 Chaning 방법을 이용해 해시 충돌 문제를 해결할 수 있습니다.
Chaining 방법은 해시 충돌이 발생했을 때 이를 동일한 bucket에 저장 하되 나중에 저장되는 값을 연결리스트 형태로 저장하는 방법입니다.
Chaining 을 통해 hash table 을 생성하였을때 기능들의 시간복잡도는 까지 늘어날 수도 있다는 단점이 있습니다.
linked list 의 요소들을 처음부터 하나씩 찾아야하므로
Open Addressing (Close hashing)
다음으로 해시 충돌을 해결할 수 있는 방법으로 Open Addressing 방법이 있습니다.
Close hashing, Linear probing 이라고 부르기도 합니다.
Open Addressing 방법은 해시 충돌이 일어날 경우, 비어있는 hash를 찾아 데이터를 저장하는 기법입니다.
따라서 Chaining 방법에서는 하나의 hash 에 여러 value 들이 저장되었던 반면, Open addressing 에서는 무조건적으로 1개의 해시와 1개의 value 만이 매칭되게 됩니다.
이때, 비어있는 hash 를 찾는 방법으로 단순히 한칸씩 옆으로 옮기며 빈 공간(bucket) 를 찾아가는 linear probing 방법이 있습니다.
이러한 linear probing 방법을 사용하면 데이터들이 특정 위치에만 밀집하는 clustering 문제가 발생할 수 있습니다.
이 문제를 해결하기위해 을 건너뛰어 빈 공간(bucket) 를 찾아가는 quadratic probing 방법도 있습니다.
파이썬으로 Hash 구현
파이썬을 이용하여 Hash 데이터 구조와 여러 기능을 간단히 구현할 수 있습니다.
먼저, hash table 을 파이썬 리스트를 이용하여 아래와 같이 구현할 수 있습니다.
class HashTable:
def __init__(self, table_size):
self.size = table_size # 총 공간(bucket) 수
self.hash_table = [0 for a in range(self.size)] # 빈 hash table 생성
def getKey(self, data): # key(문자) 첫 문자의 유니코드를 반환
self.key = ord(data[0])
return self.key
def hashFunction(self, key): # key 의 hash 값을 반환
return key % self.size
def getAddress(self, key): # hash address 를 반환
myKey = self.getKey(key)
hash_address = self.hashFunction(myKey)
return hash_address
def save(self, key, value): # 데이터 저장
hash_address = self.getAddress(key)
self.hash_table[hash_address] = value
def read(self, key): # key 에 해당하는 value 반환
hash_address = self.getAddress(key)
return self.hash_table[hash_address]
def delete(self, key): # 데이터 삭제
hash_address = self.getAddress(key)
if self.hash_table[hash_address] != 0:
self.hash_table[hash_address] = 0
return True
else:
return False
if __name__ == '__main__':
h_table = HashTable(8)
h_table.save('a', '1111')
h_table.save('b', '2222')
h_table.save('c', '3333')
h_table.save('d', '4444')
print(h_table.hash_table) # [0, '1111', '2222', '3333', '4444', 0, 0, 0]
print(h_table.read('d')) # 4444
h_table.delete('d')
print(h_table.hash_table) # [0, '1111', '2222', 0, '4444', 0, 0, 0]
다음으로 hash table 문제를 해결할 수 있는 방법 중 Chaining 방법을 구현해보겠습니다.
이론상으로 chaining 방법은 linked list 를 사용하여 구현할 수 있지만 파이썬에서는 이중리스트를 이용하여 더욱 간결하게 구현할 수 있습니다.
class Chaining:
def __init__(self, table_size):
self.size = table_size
self.hash_table = [0 for a in range(self.size)]
def getKey(self, data):
self.key = ord(data[0])
return self.key
def hashFunction(self, key):
return key % self.size
def getAddress(self, key):
myKey = self.getKey(key)
hash_address = self.hashFunction(myKey)
return hash_address
def save(self, key, value):
hash_address = self.getAddress(key)
if self.hash_table[hash_address] != 0: # 해시 충돌 시
for a in range(len(self.hash_table[hash_address])): # 빈 bucket 탐색
if self.hash_table[hash_address][a][0] == key: # key 에 맞는 value 매칭
self.hash_table[hash_address][a][1] = value
return
self.hash_table[hash_address].append([key, value])
else:
self.hash_table[hash_address] = [[key, value]]
def read(self, key):
hash_address = self.getAddress(key)
if self.hash_table[hash_address] != 0: # 해시 충돌 시
for a in range(len(self.hash_table[hash_address])):
if self.hash_table[hash_address][a][0] == key: # 일치하는 key 값 찾음
return self.hash_table[hash_address][a][1] # 일치하는 value 반환
return False
else:
return False
def delete(self, key):
hash_address = self.getAddress(key)
if self.hash_table[hash_address] != 0:
for a in range(len(self.hash_table[hash_address])):
if self.hash_table[hash_address][a][0] == key:
if len(self.hash_table[hash_address]) == 1:
self.hash_table[hash_address] = 0
else:
del self.hash_table[hash_address][a]
return
return False
else:
return False
if __name__ == '__main__':
h_table = Chaining(8)
h_table.save('aa', '1111')
print(h_table.read('aa')) # 1111
data1 = 'aa'
data2 = 'ab'
print(ord(data1[0])) # 97
print(ord(data2[0])) # 97 같은 hash 값을 가짐 -> 해시 충돌
h_table.save('ab', '2222')
print(h_table.hash_table) # [0, [['aa', '1111'], ['ab', '2222']], 0, 0, 0, 0, 0, 0]
print(h_table.read('aa')) # 1111
print(h_table.read('ab')) # 2222
h_table.delete('aa')
print(h_table.hash_table) # [0, [['ab', '2222']], 0, 0, 0, 0, 0, 0]
print(h_table.delete('Data')) # False
이어서 해시 충돌을 해결할 수 있는 방법 중 하나인 Open Addressing 방법을 파이썬으로 구현해보겠습니다.
class OpenAddressing:
def __init__(self, table_size):
self.size = table_size
self.hash_table = [0 for a in range(self.size)]
def getKey(self, data):
self.key = ord(data[0])
return self.key
def hashFunction(self, key):
return key % self.size
def getAddress(self, key):
myKey = self.getKey(key)
hash_address = self.hashFunction(myKey)
return hash_address
def save(self, key, value):
hash_address = self.getAddress(key)
if self.hash_table[hash_address] != 0: # hash 의 값이 이미 존재할때 (해시충돌)
for a in range(hash_address, len(self.hash_table)):
if self.hash_table[a] == 0:
self.hash_table[a] = [key, value]
return
elif self.hash_table[a][0] == key:
self.hash_table[a] = [key, value]
return
return None
else: # hash 가 비었을때
self.hash_table[hash_address] = [key, value]
def read(self, key):
hash_address = self.getAddress(key)
for a in range(hash_address, len(self.hash_table)):
if self.hash_table[a][0] == key:
return self.hash_table[a][1]
return None
def delete(self, key):
hash_address = self.getAddress(key)
for a in range(hash_address, len(self.hash_table)):
if self.hash_table[a] == 0:
continue
if self.hash_table[a][0] == key:
self.hash_table[a] = 0
return
return False
if __name__=='__main__':
h_table = OpenAddresing(8)
data1 = 'aa'
data2 = 'ab'
print(ord(data1[0]), ord(data2[0])) ## 97 97 -> 해시 충돌
h_table.save('aa', '1111')
h_table.save('ab', '2222')
print(h_table.hash_table) # [0, ['aa', '1111'], ['ab', '2222'], 0, 0, 0, 0, 0]
print(h_table.read('ab')) # 2222
h_table.delete('aa')
print(h_table.hash_table) # [0, 0, ['ab', '2222'], 0, 0, 0, 0, 0]
[ Java의 HashMap(해시맵) vs HashTable(해시테이블) ]
Java 개발자라면 (Key,Value)로 저장하는 익숙한 자료구조인 HashMap이 있다. 그렇다면 Java에서 HashTable과 HashMap의 차이가 당연히 있을 텐데, 그 차이는 동기화 지원 여부에 있다.
// 해시테이블의 put
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
// 해시맵의 put
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}위의 코드에서 첫번째 put은 해시테이블의 put이며, 두번째 put은 해시맵의 put이다. 첫번째 해시테이블의 put에는 synchronized 키워드가 붙어있는 것을 확인할 수 있는데, 이것은 병렬 프로그래밍을 할 때 동기화를 지원해준다는 것을 의미한다. 이것은 해당 함수를 처리하는 시간이 조금 지연됨을 의미힌다.
그렇기 때문에 우리는 병렬 처리를 하면서 자원의 동기화를 고려해야 하는 상황이라면 해시테이블(HashTable)을 사용해야 하며, 병렬 처리를 하지 않거나 자원의 동기화를 고려하지 않는 상황이라면 해시맵(HashMap)을 사용하면 된다.
원글 출처:https://ai-rtistic.com/2022/01/29/data-structure-hash/