
클러스터 인덱스
- 클러스터 인덱스는 데이터 위치를 결정하는 키 값이다.
- 인덱스들을 통해 PK값들을 통해 결국 주소를 찾아야하는데 클러스터인덱스가 데이터주소가 저장되어 있는 인덱스이다.
- MySQL의 PK는 클러스터 인덱스다.
- MySQL에서 PK를 제외한 모든 인덱스는 PK를 가지고 있다.
클러스터 인덱스는 데이터위치를 결정한다.
| 클러스터 키 | 데이터 주소 |
| 1 | A |
| 2 | B |
| 3 | C |
| 5 | D |
- 위와 같은 인덱스가 있을 때 클러스터 4번이 Insert되면 아래 처럼 클러스터 순서에 맞게 위치가 된다. 데이터 주소도 밀리게 된다.
| 클러스터 키 | 데이터 주소 |
| 1 | A |
| 2 | B |
| 3 | C |
| 4 | D |
| 5 | F |
- 클러스터 키 순서에 따라서 저장 위치가 변경되기 때문에 클러스터 키 삽입/갱신시에 성능이슈 발생 (데이터가 전부 땡겨지겨나 밀리기 때문)
MySQL의 PK는 클러스터 인덱스다
- PK도 클러스터 인덱스이기에 삽입/갱신시에 성능이슈가 발생할 수 있다.
- PK : Auto Increment vs UUID(유효아이디) -> UUID는 increment pk보다 더 많은 저장 장소를 필요로 한다. 테이블과 인덱스의 크기가 커진다. 애플리케이션 내부로는 increment로 하는 것이 좋다
MySQL에서 PK를 제외한 모든 인덱스는 PK를 가지고 있다.
- PK의 사이즈가 인덱스의 사이즈를 결정한다.
- 인덱스가 PK가 아니라 주소를 가지고 있다면 데이터순서가 바뀔 때마다 인덱스도 갱신이 되어야 한다 -> 비효율
- 센컨더리 인덱스만으로는 데이터를 찾아갈 수 없다. -> PK인덱스를 항상 검색해야함
- PK를 활용한 검색이 매우 빠름. 특히 범위 검색시
- 세컨더리 인덱스들이 PK를 가지고 있어 커버링에 유리, 인덱스까지만 가서 데이터를 반환해줄 수 있다.
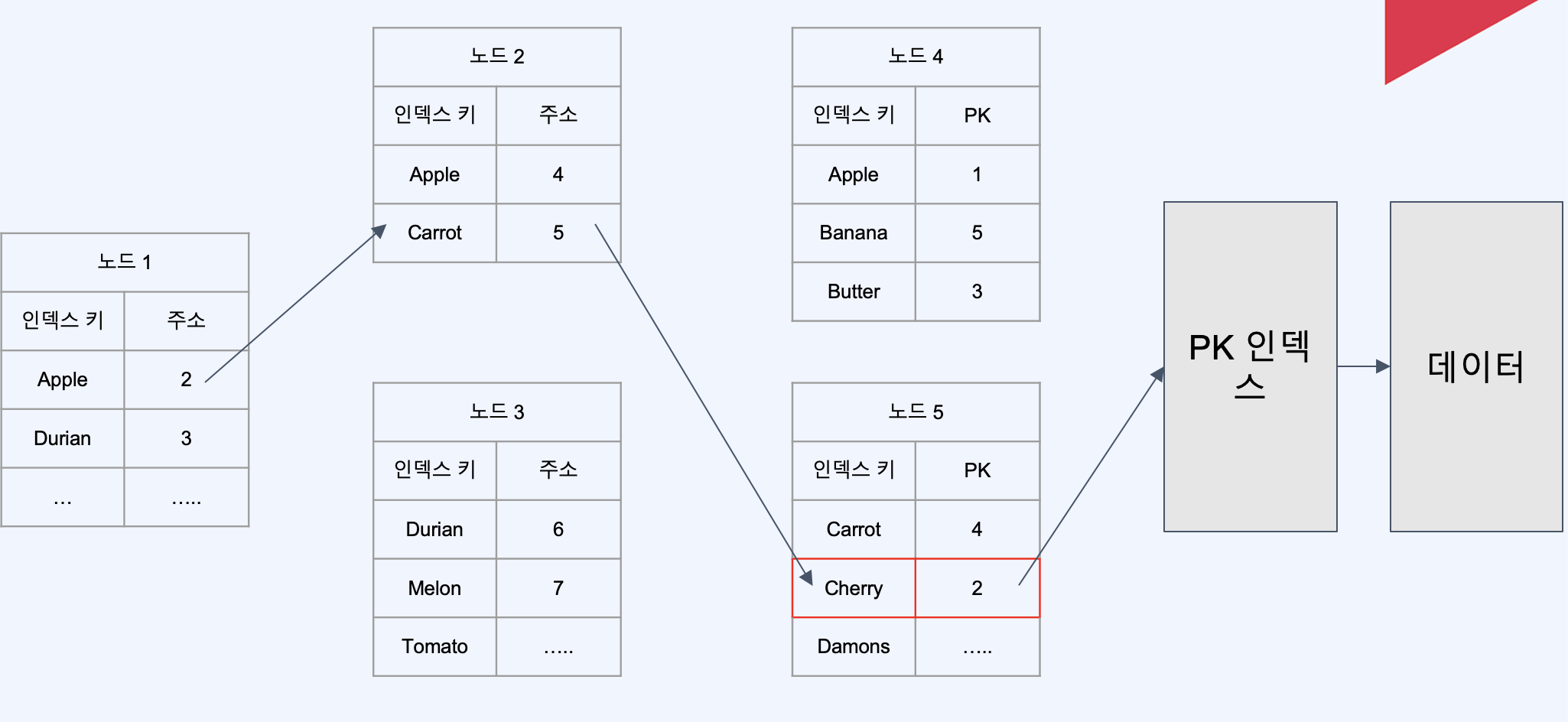
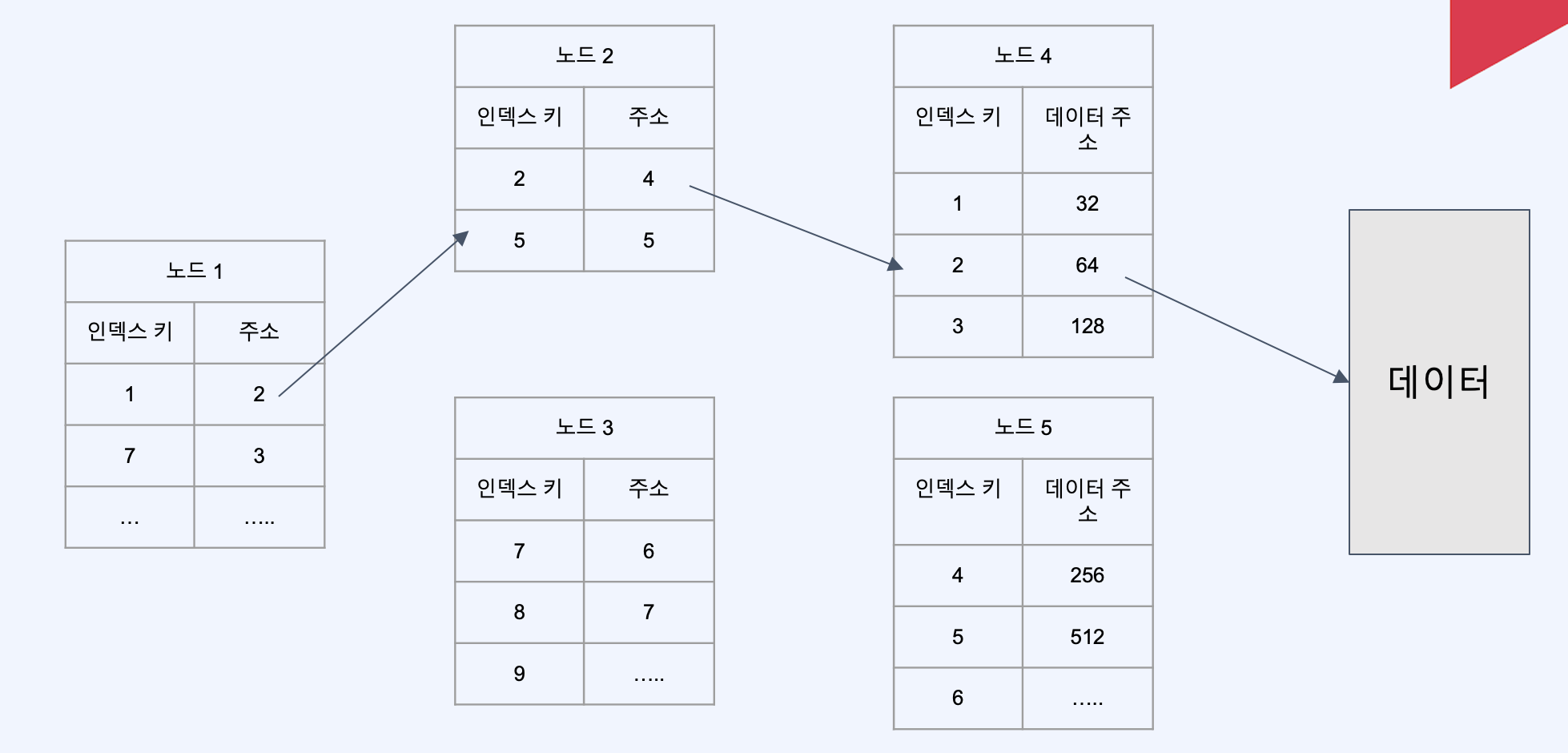
위의 그림과정에서 PK를 찾은 후 아래 그림의 과정으로 넘어간다. 아래그림은 PK인덱스의 상황
'Computer Science > 데이터베이스' 카테고리의 다른 글
| 엔티티(Entity) (0) | 2023.06.03 |
|---|---|
| 데이터 모델링 (0) | 2023.06.03 |
| 인덱스(요약) (0) | 2023.06.03 |
| 데이터베이스의 성능 (0) | 2023.06.03 |
| 데이터베이스 정규화 (0) | 2023.06.01 |