
인덱스
- DB검색을 효율적(빠르게)하기 위한 보조테이블이라고 생각하면 됨
- 조회성능을 높이지만 쓰기,갱신의 속도를 낮춘다. 또한 저장공간도 잡아먹는다. -> 균형을 맞추는 것이 중요하다.
- 정렬된 자료구조
- 이를 통해 탐색범위를 최소화
- 예) 제일많은 나이를 찾기 -> 나이를 기준으로 한 인덱스의 맨뒤를 보면됨
- 인덱스도 테이블이다.
- 인덱스의 핵심은 탐색범위를 최소화하는 것

인덱스 사용의 예시(로그북 프로젝트)
현재 진행하고 있는 로그북 앱 프로젝트로 예시를 들면 로그북DB에는 로그테이블이 있다. 그중에서 다이빙포인트가 라우라우비치인 로그들을 불러오고 싶다. 이때 인덱스를 사용하지 않는다면 모든 로그들을 탐색해서 정보를 가져온다. 정보가 매우 많다면 이는 오래걸리는 작업일 것이다. 하지만 다이빙포인트로 인덱스를 생성하여 탐색한다면 먼저 다이빙포인트인덱스에서 라우라우비치포인트를 찾을 것이다. 그러면 라우라우비치 로그들을 빠르게 찾을 수 있다.
또 다른 예로는 포인트가 라우라우비치이고 날씨가 맑음인 로그들의 정보를 가져오고 싶다면 포인트인덱스로 탐색범위를 줄여서 보다 빠른 탐색이 가능해 진다. 하지만 조회시에는 빠르지만 로그작성시에는 인덱스에도 정보가 추가되어야하기 때문에 쓰기에는 불리해진다.
인덱스는 B+ Tree 자료구조를 사용한다
- B+ Tree
- 삽입 / 삭제시 항상 균형을 이룬다.
- 하나의 노드가 여러 개의 자식 노드를 가질 수 있음
- 리프노드에만 데이터 존재
- 연속적인 데이터 접근 시 유리
- 트리는 높이를 최소화하는 것이 중요 (트리의 높이에 따라 복잡도가 달라짐)
- 아래 그림은 실제 데이터베이스(MySQL)에서의 과정이다. cherry를 찾는과정, 알파벳순
MySQL에서는 PK를 가지고 있다. 그래서 MySQL에서 PK가 매우 중요하다. PK처리하고 노드들이 PK를 다 들고 있기때문에 트리구조가 바뀔 수도 있다.
오라클에서는 PK대신 데이터주소가 들어있다.

인덱스 사용법
##인덱스 생성법##
create index POST__index_member_id on POST(memberId);
create index POST__index_created_date on POST(createdDate);
create index POST__index_member_id_created_date on Post(memberId, createdDate);
또는 GUI에서 추가
##인덱스사용을 강제하여 조회하는 쿼리##
SELECT createdDate , memberId, Count(id)
FROM POST use index (POST__index_member_id)
WHERE memberId = 4 and createdDate between '1900-01-01' and '2023-01-01'
GROUP BY memberId, createdDate;
## 인덱스사용을 강제하지 않으면 가장 유리한 인덱스를 적용시켜 탐색한다
## -> 떄로는 가장 좋은 인덱스를 선택 안하는 경우도 있다 -> explain을 통한 옵티마이저분석으로 알아볼 수 있다.
효율적인 인덱스 설계
- WHERE 절에 사용되는 열 (WHERE 절에 사용되는 열이라도 자주 사용해야 가치가 있음)
- SELECT 절에 자주 등장하는 컬럼들을 잘 조합해서 INDEX로 만들어두면 INDEX 조회 후 다시 데이터에서 조회할 필요가 없으므로 빠르게 검색이 가능하다.
- JOIN절에 자주 사용되는 열에는 인덱스의 효율이 좋음.
- ORDER BY 절에 사용되는 열은 데이터 페이지가 자동 정렬됐기 때문에 클러스터형 인덱스가 유리
- 데이터가 매우 많아 열(row)에 광범위한 값이 포함된 경우
- 열(row)에 많은 널 값이 포함된 경우
- 하나 이상의 열(row)이 where절이나 join 조건에서 함께 사용되는 경우
- 테이블이 크고 대부분의 query가 2~4% 미만의 행을 검색할 것으로 예상되는 경우
참고: 외래키는 자동으로 외래키 인덱스 만듬
금지해야 할 인덱스 설계
- 대용량 데이터가 자주 입력되는 경우,
클러스터형 인덱스의 경우 빈번한 페이징이 일어나기 때문에 부하가 생긴다.
따라서 인덱스가 필요한 경우 primary(클러스터) 대신 unique만 설정하는 게 좋을 수 있다. - 데이터 중복도가 높은 열은 익덱스 효과가 없다.
예를 들어 성별 열에 M, F만 있다고 하면 인덱스를 안쓰는 게 낫다.
따라서 일반 보조 인덱스보다 unique 보조 인덱스가 빠른 이유가 이것이다. - 자주 사용되지 않으면 성능 저하를 초래할 수 있음. (INSERT만 주구장창 하는 시스템이라면, 사용해보지도 못하고 데이터 입력에 걸리는 작업량만 많아진다)
- 인덱스가 탐색범위를 좁혀주지 못하면 오히려 인덱스와 테이블 두개를 탐색하여야 해서 오히려 역효과가 날 수도 있다.
인덱스 주의점
- 인덱스필드 가공
- 타입을 잘못넣어 줬을 경우 DB가 인덱스를 이용 안할 수도 있다. (WHERE age="1", age는 int타입인데 문자열을 넘겨준 경우)
- 값을 가공한 경우 DB가 인덱스를 안이용할 수도 있다. (WHERE age*10=1, .인덱스의 키값이 age로 되어 있기에 가공을 하면 못찾는다.)
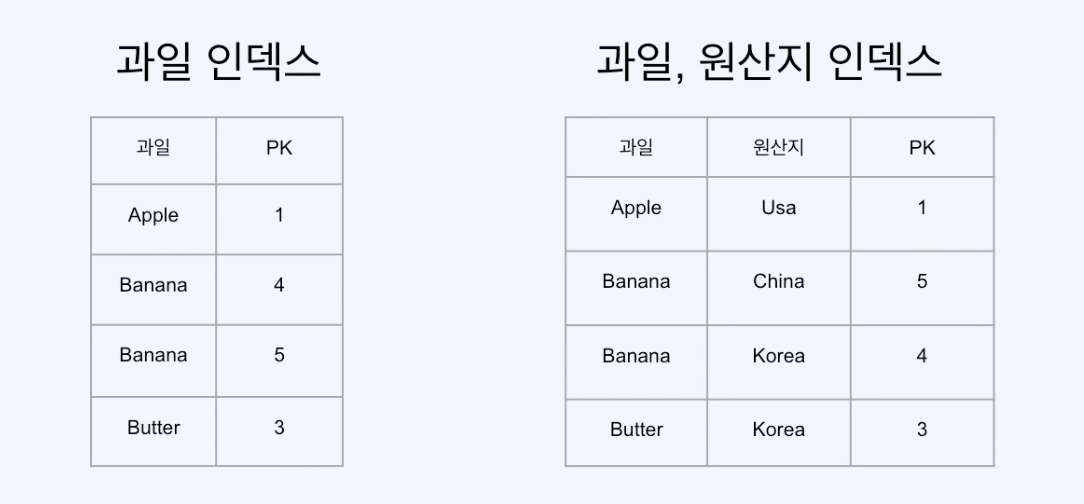
- 복합 인덱스
- 복합 인덱스는 첫번째 컬럼(선두컬럼)으로 정렬을 하고 같다면 두번째 필드로 정렬을 한다.
- 아래 그림에서는 과일로 정렬 후 같다면 원산지로 정렬한다.
- 이러한 복합 인덱스를 이용하게 된다면 WHERE문에 원산지만 들어오면 인덱스의 역할을 못한다.
- 반면에 과일이 WHRER문에 들어오거나 과일과 원산지가 같이 들어온다면 인덱스의 역할을 한다.
- 하나의 쿼리에는 하나의 인덱스만 이용
- 하나의 쿼리에는 하나의 인덱스만 탄다.
- 기본적으로 여러 인덱스 테이블을 동시에 탐색하지 않음 (index merge hint를 사용하면 가능)
- WHERE, ORDER BY, GROUP BY를 혼합해서 사용할 때에는 인덱스를 잘 고려해야 함 (WHRER문을 인덱스를 통하여 가져왔더라도 ORDER BY등이 인덱스를 못타면 가져온 데이터를 정렬해야 하기때문에)
- 의도대로 인덱스가 동작하지 않을 수 있음. sql문의 explain으로 확인(sql문 앞에 explain을 붙이면 옵티마이저, 어떤 인덱스를 이용했는지 알 수 있다.)
- 인덱스도 비용이다. 쓰기를 희생하고 조회를 얻는 것, 데이터가 적다면 안쓰는 것이 오히려 좋을 수도 있다.
- 꼭 인덱스로만 해결할 수 있는 문제인가? 생각해보기
- 인덱스를 설정할 때는 Cardinality가 높은, 데이터의 식별정도가 높은 값으로 설정하는 것이 좋다. (안좋은 예: 성별(남,여) 두가지밖에 없다. 탐색범위를 반틈으로 줄이는 영향밖에 없다.)
'Computer Science > 데이터베이스' 카테고리의 다른 글
| 데이터 모델링 (0) | 2023.06.03 |
|---|---|
| 클러스터 인덱스 (0) | 2023.06.03 |
| 데이터베이스의 성능 (0) | 2023.06.03 |
| 데이터베이스 정규화 (0) | 2023.06.01 |
| MySQL (0) | 2023.06.01 |