
homogeneous aggregationProgramming이란?
- Programs = Algorithms+ Data Structures
- 입력 데이터를 적합한 절차를 통해 처리하는 것
- 프로그래밍 언어: 데이터와 알고리즘을 기술해야 함
- 내가 해야할 문제의 해결방법이 해당 언어에서 직접 제공된다면 그것으로 충분, 그렇지 않다면 무엇인가 만들어야 함(Data Type+Operations)
Encapsulation
- Data와 Operation을 하나의 묶음(capsule)으로 묶을 수 있는 장치
- Encapsulation=information hiding
사용자 정의 데이터 타입
네가지 Basic Mechanisms
- Structured Data: 복합 데이터를 만들 수 있는 기능
- Subprograms: 새로운 연산을 정의할 수 있는 기능
- Type Declarations: 특정 부류의 데이터와 이와 관련된 연산을 하나로 묶어 새로운 데이터 타입을 정의할 수 있는 기능
- Inheritance: 기존 데이터 타입의 기능을 모두 포함하며 더욱 확장된 데이터 타입을 생성할 수 있는 기능
분류
- 필수 기능: structured data+ subprogram
- 고급 기능: type declarations + inheritance
Structured Data
- 다른 데이터 객체를 원소(elements)나 요소(components)로 하여 구성된 데이터 객체
- 원소=요소(이 파트에서는 같은 것으로 취급하겠음)
- 예시: 배열(Array), 레코드(record or structure), 스택(stack), 리스트(list), 집합(set)
- Structured Data의 이슈
- 요소 선택 방법
- 메모리 관리 방법
Specification of Data Structured Types
요소개수
- 고정크기: array, record
- 가변크기: list, set, tables, files
- 주의: 가변 크기 배열도 있음
요소 타입
- 동형(homogeneous) 구조: array, set
- 이형(heterogeneous) 구조: record, list
- 주의: 동형 리스트만 허용하는 경우도 있음
요소 선택 방법
- 임의 접근/순차 접근
최대 요소 개수
- 가변 크기의 경우 최대 요소 개수가 지정될 수 있음
구성 방법
- 배열 차원
- variant records
Operations on Data Structures
데이터 구조에 관한 연산
- 요소 선택
- 임의 선택: 임의 순서로 요소 선택
- 순차 선택: 정해진 순서에 따라 선택
- 전체 구조에 대한 연산
- 예: assignments, union of sets, transpose of a matrix
- 요소의 삽입/삭제
- 데이터 구조의 생성/소멸
예시

Data Structures 구현
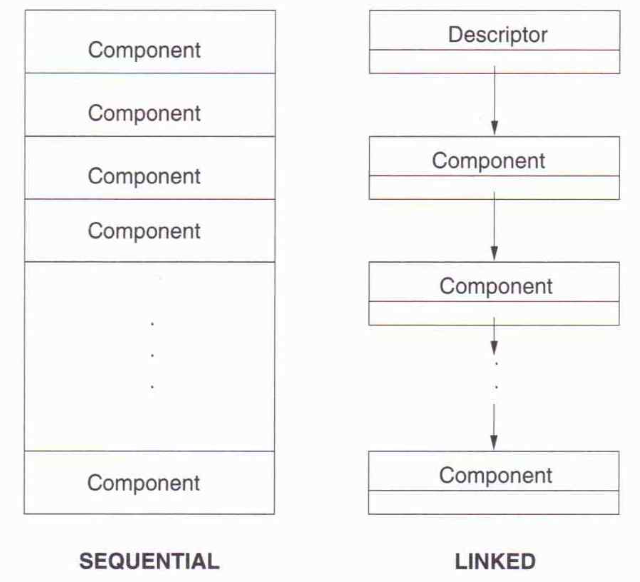
저장 공간 형태
- 연속된 형태
- 연결된 형태
연산 구현
- 연속된 경우 selection: base-address + offset
- 연결된 경우 selection: head address + follow links
저장 공간 관리
- 객체의 지속시간(lifetime) 관리
- 지속시간이란? storage binding이 유지되는 시간, 즉 해당 객체의 공간이 존재하는 시간
저장공간 관리의 문제점
Garbage(떠돌이 객체)
- 참조 경로를 잃어 버린 객체
- 객체의 deadlocation이 너무 늦음
- dangling object라고도 함
- 위험하진 않지만 공간의 낭비 -> 메모리 누수
Dangling Reference(외로운 참조)
- 이미 해제된 공간을 가리키는 참조 경로
- 객체의 deadlocation이 너무 빠름
- 다른 용도의 공간을 훼손할 수 있음 -> 심각한 위험
Data Structures의 타입 검사
선언문의 예(C언어): float A[20]
- 배열
- 1차원 배열
- 요소개수는 20개
- 인덱스는 0부터 19까지 사용가능
- 요소 타입은 float
Structured type의 타입 검사를 복잡하게 하는 요인
- selector를 통해 선택한 요소가 실제로 존재하는가 검사해야 함
- 배열의 경우 첨자의 범위 검사필요
- 선택된 요소의 타입도 다시 고려해야 함
- 예시)A[2][3].link -> item
Arrays(배열, vectors)
배열이란?
- 같은 타입의 유한한 개체가 일렬로 나열된 것
- homogeneous aggregation (동형 구조)
배열(vertor)의 attributes
- 요소 개수
- 요소의 타입
- 첨자(subscript): 통산 자연수이지만, 임의의 enumeration일 수도 있음
Array Operations
Component Operations
- 요소 선택: 통상 첨자 연산으로 처리
- 요소 갱신: 통상 첨자 연산으로 처리
- 요소 삽입 및 삭제: 가변 벡터의 경우에만 허용
Whole Array Operation
- 크기(size)
- 배열 대입(array assignment)
- 내적(inner product)
- 외적(cross product)
Whole Array Operation의 문제점
- 중간결과(array일수도 있음)를 저장할 공간 필요
Array Imprementation
- 이 파트에서는 일차원 배열만 고려한다,
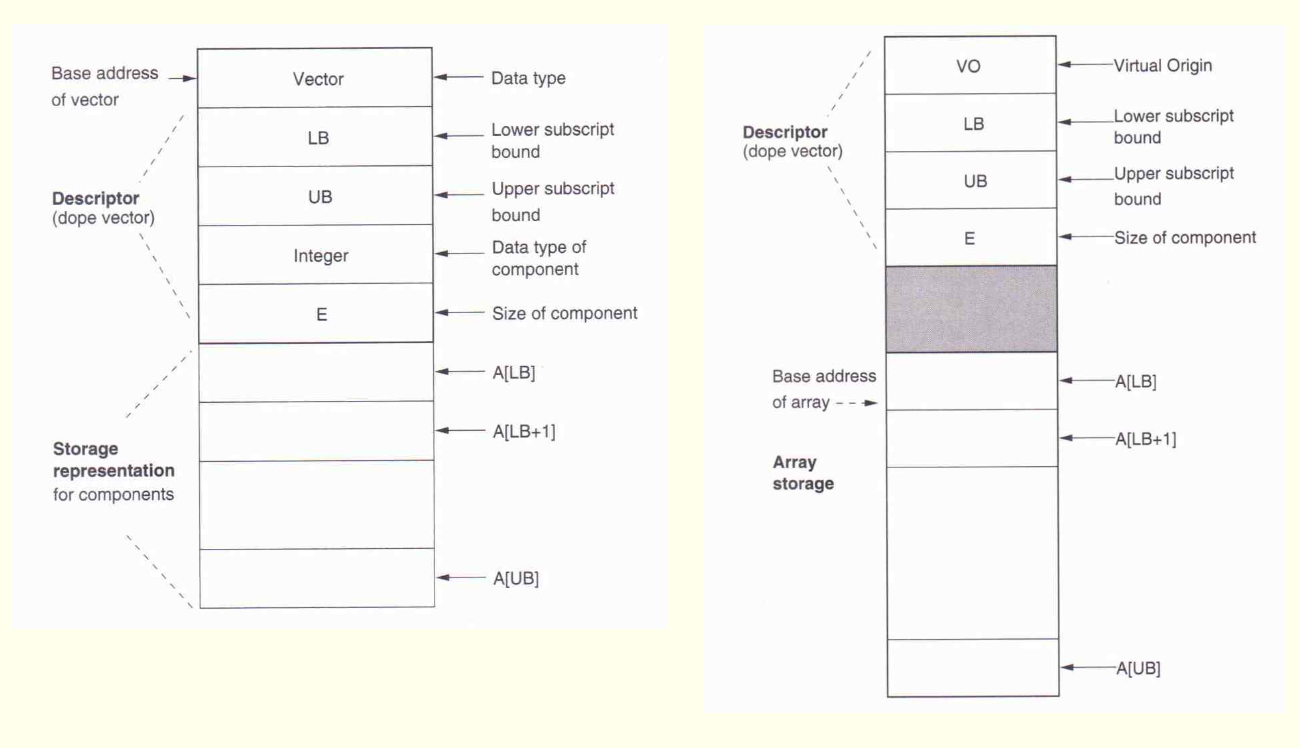
- 참조 공식(accessing formula)
- 할당된 첫 번째 요소의 주소가 a, 요소의 크기가 E라고 하면 I번째 요소의 주소 Ivalue(a[I])는
Ivalue(A[I])
= a + (I-LB) x E
= (a-LB xE) +I x E
= K + I x E - K는 정적시간에 결정 가능
- 가상원점이라고 함
- 할당된 첫 번째 요소의 주소가 a, 요소의 크기가 E라고 하면 I번째 요소의 주소 Ivalue(a[I])는
- Dope Vector
- 참조가 올바른가 검사하려면 UB도 알아야 함
- VO: Virtual origin
- LB: Lower subscript Bound
- UB: Upper subscript Bound
- E: 요소의 크기
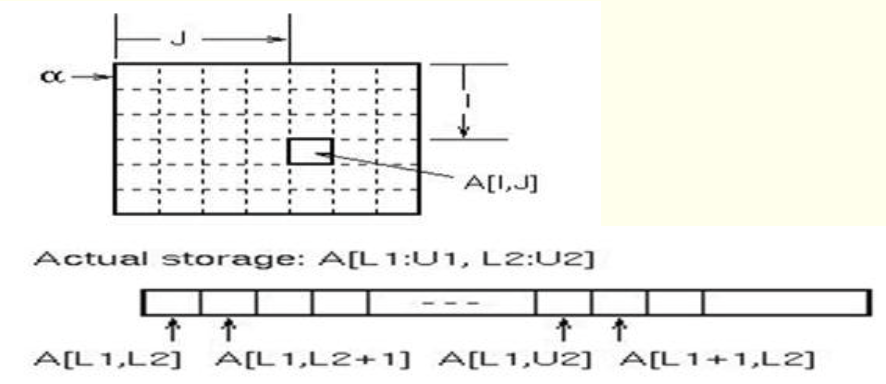
2차원 배열
2차원 배열 구현 방법
- row-major: 행들의 1차원 배열
- column-major: 열들의 1차원 배열
- 대개 row-major로 구현되나 예전 FORTRAN의 경우에는 column-major로 구현되었음
- C는 2차원 배열이 없음: 배열의 배열로 2차원 지원

Storage Representation
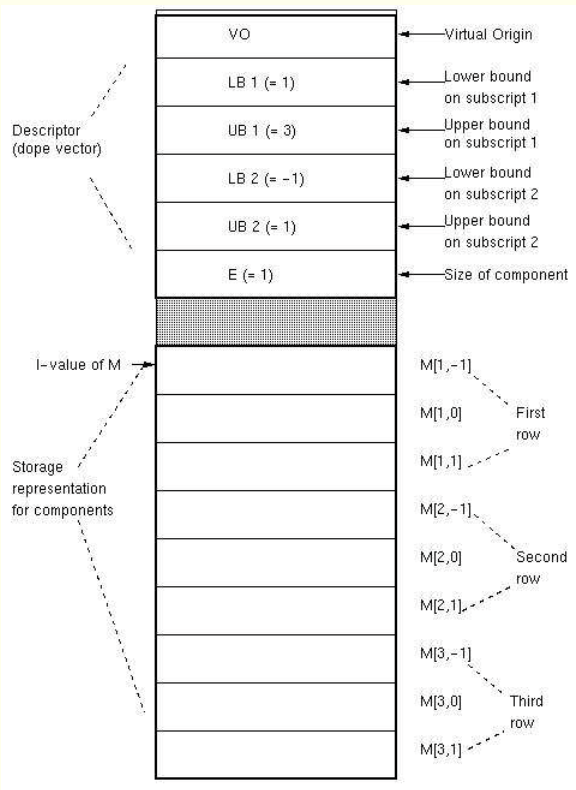
Dope vector
- 가상원점 VO
- 양 끝들(LBs, UBs)
- 요소 크기 E
아래 그림은 array[1..3,-1..1] of M 의 타입에 대한 공간 할당 내역 (여기서 타입 M의 크기는 1)
다차원 배열

Slices
그 자체가 배열인 배열의 하부 구조(substructure)
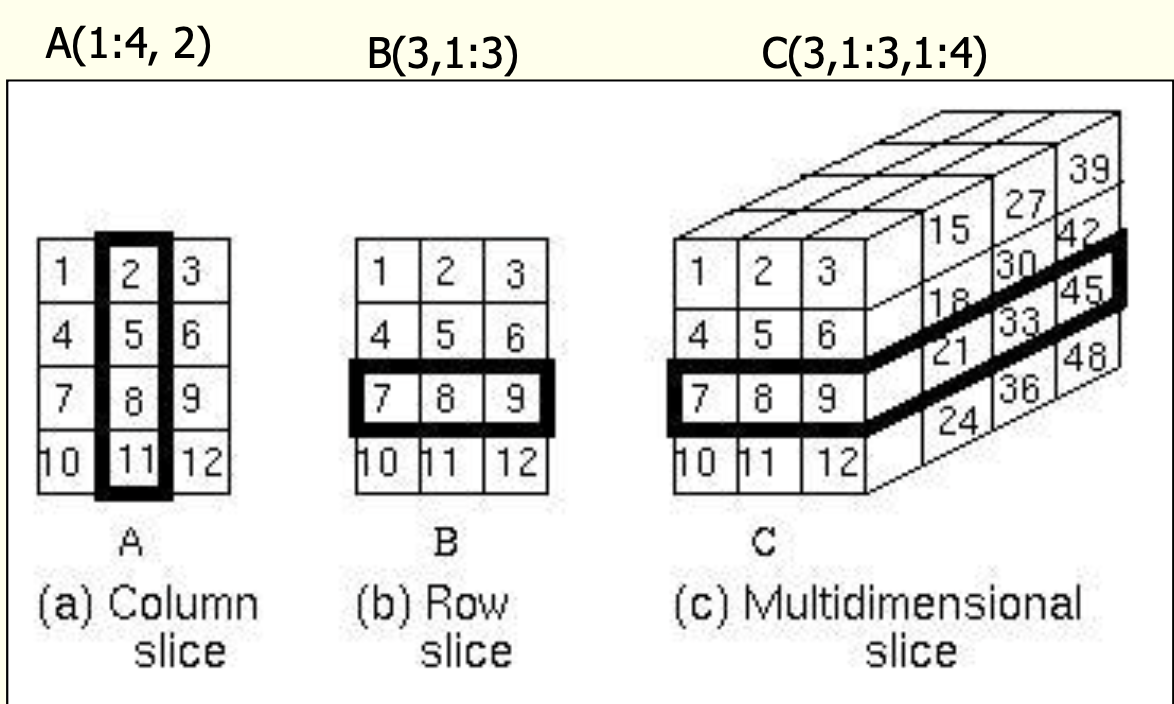
연관 배열(Associative Arrays)
연관배열
- 이름을 첨자로 사용하는 배열
- (key,value)로 이루어진 참조 표로 간주할 수 있음
- 참조표(lookup table) 또는 사전(dictionary)라고도 함
연산
- 첨가(add): 새로운 (key,value)를 추가
- 변경(reassign): 기존 key의 value를 바꿈
- 삭제(remove): 기존 (key,value)를 삭제
- 참조(lookup): 특정 key와 연관된 값을 참조
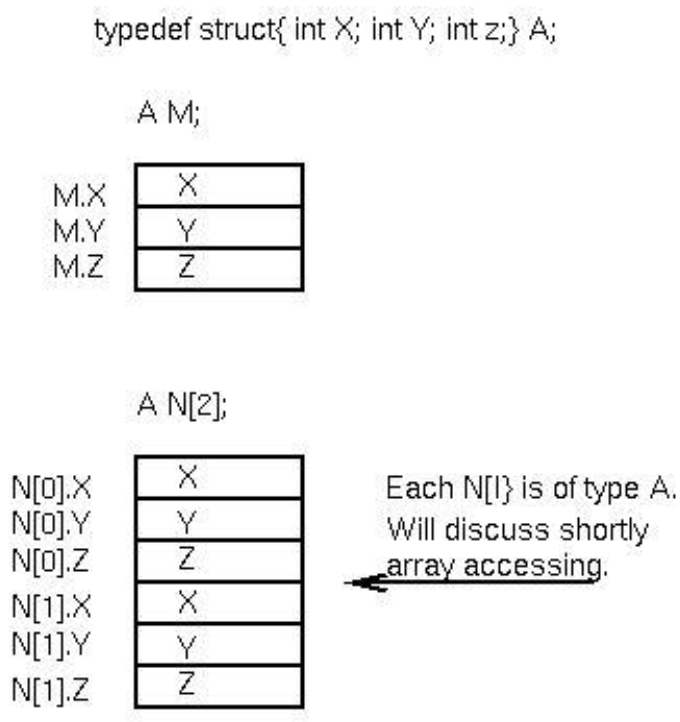
Records
개요
- (일반적으로) 다른 타입의 정해진 수의 요소들을 하나로 모은 것
- heterogeneous aggregation (이형 구조)
속성
- 요소 개수
- 요소 타입
- 요소 선택자
연산
- "MOVE CORRESPONDING" operation
- e.g. MOVE CORRESPONDING INPUREC TO EMPLOYEE
Structures in C
- selector: 필드명
- Tag or Type
- C에서는 tag와 type을 구별함
- C++에서는 tag를 타입처럼 사용함
- 예(in C)
struct A{...};
typedef struct A A;
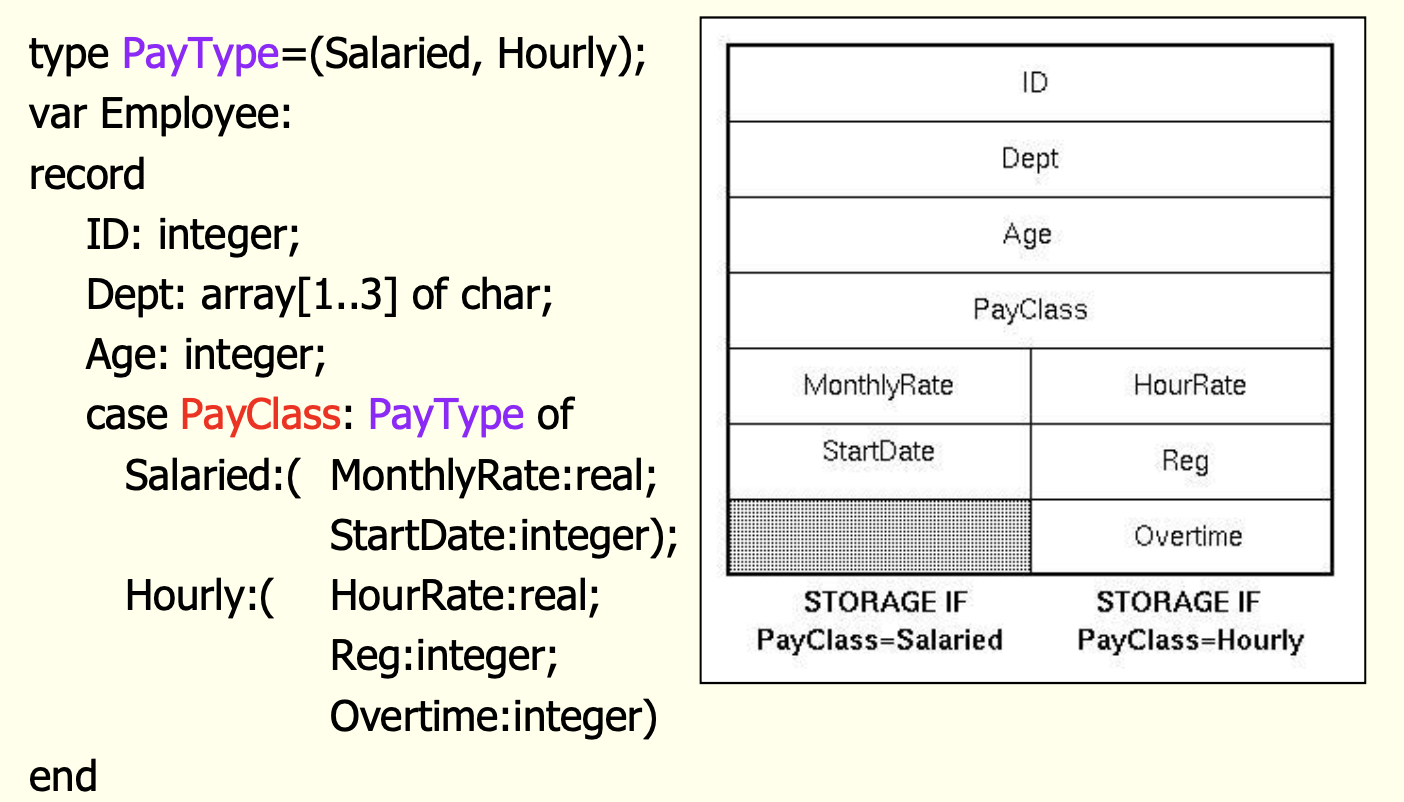
Variant Records
개요
- 하나의 타입에 여러 다른 형태의 타입이 올 수 있지만, 동시에 여러 값을 갖지는 않음
- 모든 필드의 좌측값이 같음(same I-value)
- 단순히 공간 효율성을 위해 존재하는 타입
속성 및 연산
- record와 동일
문제점: 타입 검사
- 동적 검사
- 검사하지 않음
분류
- 구분자(discriminator) 여부에 따라..
- free-union (non-discriminated variant record)
- discriminated-union (discriminated variant record)
Union in C

Variant Record in Pascal

List
개요
- 순차 목록
배열과의 차이점
- 고정 길이가 아님
- 동형 요소가 아닐 수 있음 (언어에 따라 동형 요소로 제한하기도 함)
- 암시적 선언을 사용하는 경우가 많음: 별도의 선언 없이 바로 리스트 생성
대표적인 리스트 연산
- nil: 빈 리스트
- cons: 리스트에 특정 요소 접합
- head: 리시트의 첫번째 요소 (LISP의 CAR)
- tail: 첫 번째 요소를 제외한 나머지 리스트(LISP의 CDR)
리스트 예시

Sets
개요
- 서로 다른 값의 무순 모음
기본 연산
- 요소 검사
- 요소 추가 및 삭제
- 합칩합(union), 교집합(intersection), 차집합(difference)
구현
- bitmap of enumerations: 집합 크기가 제한됨
- hashing: collision 해결 필요
- rehashing
- sequential scan
- bucketing
Executable Data Objects
프로그램 != 데이터
- 통상 프로그램과 데이터는 구별함
- 프로그램과 데이터를 구별하지 않는 언어도 있음
데이터로 표현된 서브 프로그램의 예






'Computer Science > 프로그래밍언어론' 카테고리의 다른 글
| Chapter7 Inheritance (0) | 2023.06.13 |
|---|---|
| Chapter6 Encapsulation (0) | 2023.06.13 |
| Chapter5-1 Elementary Date Types (0) | 2023.04.20 |
| Chapter4 Modeling Language Properties (0) | 2023.04.20 |
| Chapter3 Language Translation Issues (0) | 2023.04.20 |