
인덱스
- 인덱스는 원하는 데이터를 쉽게 찾을 수 있도록 돕는 책의 찾아보기와 유사한 개념이다.
- 검색조건에 부합하는 데이터를 효과적으로(빠르게) 검색할 수 있도록 돕는다.
- 한 테이블은 0개~N개의 인덱스를 가질 수 있다.
- 한 테이블에 과도하게 많은 인덱스가 존재하면 INSERT, UPDATE, DELETE와 같은 DML 작업시 부하가 발생한다.
B*Tree 인덱스
- DBMS에서 널리 사용되는 가장 일반적인 인덱스이다.
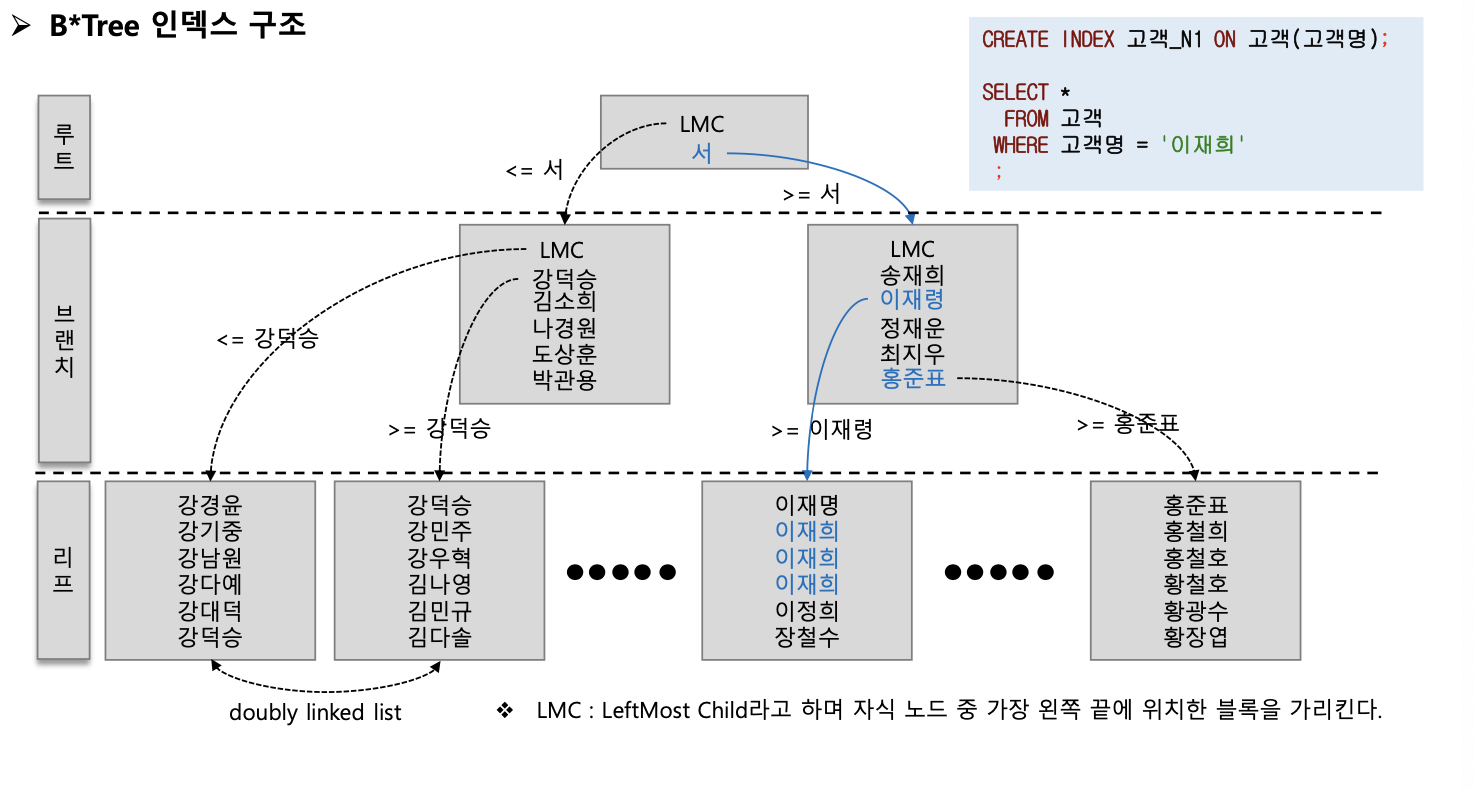
- 루트 블록, 브랜치 블록, 리프 블록으로 구성된ㄷ.
- 가장 상위에 존재하는 블록이 루트 블록이고 브랜치 블록은 분기를 목적으로 하는 블록이다.
- 리프 블록은 트리의 가장 아래 단계에 존재하는 블록이다.
- 리프 블록은 인덱스를 구성하는 컬럼의 데이터와 해당 데이터를 가지고 있는 행의 위치를 가리키는 레코드 식별자 인 ROWID로 구성되어 있다.
인덱스 구조
- 루트와 브랜치 블록에 있는 각 레코드는 하위 블록에 대한 주소 값을 갖는다. 키 값은 하위 블록에 저장된 키 값의 범위를 나타낸다.
- LMC가 가리키는 주소로 찾아간 블록에는 키 값을 가진 첫번째 레코드보다 작거나 같은 레코드가 저장돼 있다.
- 리프 블록에 저장된 각 레코드는 키 값 순으로 정렬돼 있을 뿐만 아니라 테이블 레코드를 가리키는 주소값 즉 Rowid를 갖는다.
- 인덱스 키 값이 같으면 Rowid순으로 정렬된다.
- 인덱스를 스캔하는 이유는 검색조건을 만족하는 소량의 데이터를 빨리 찾고 거기서 Rowid를 얻기 위해서이다.
ROWID의 구성
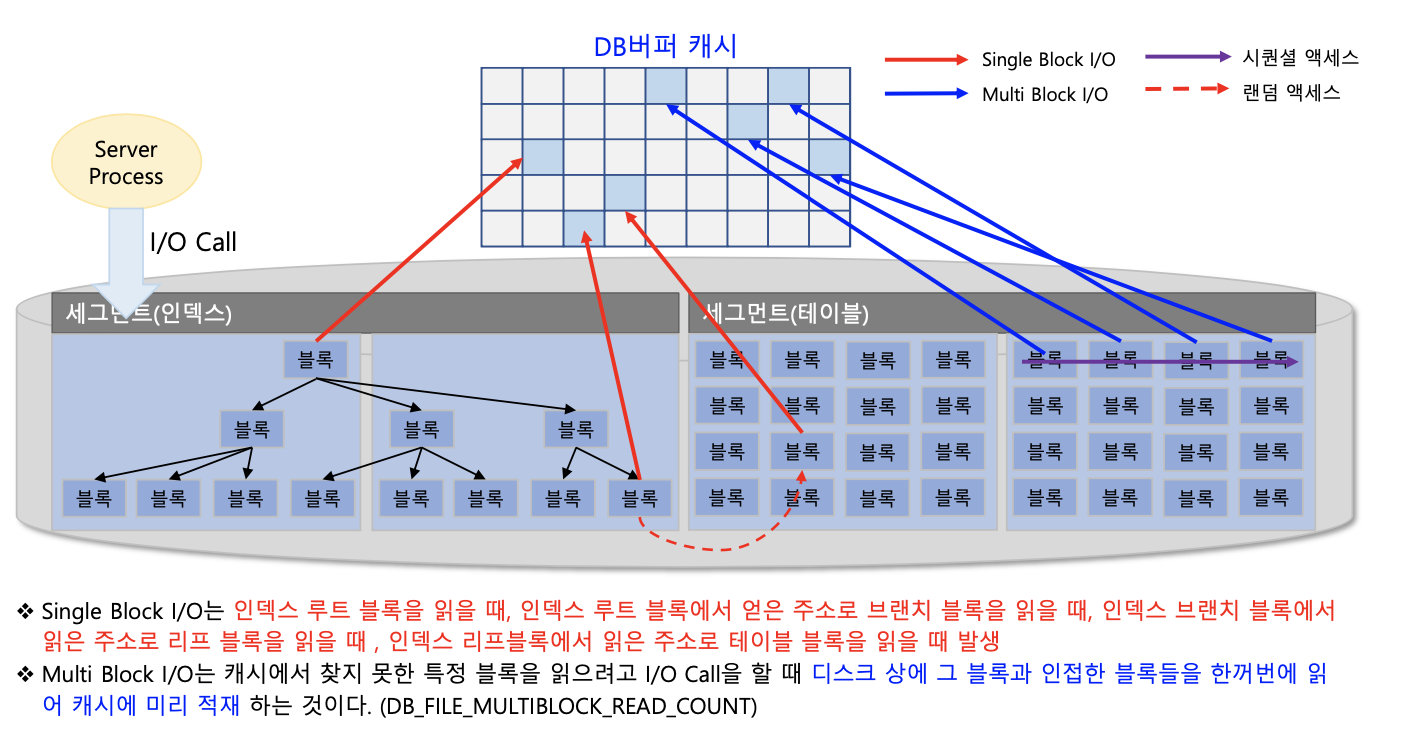
- ROWID: 데이터 블록주소 +로우 번호
- 데이터 블록 주소: 데이터 파일 번호 + 블록 번호
- 블록 번호: 데이터 파일 내에서 부여한 상대적 순번
- 로우 번호: 블록 내 순번
Single Block I/O vs Multi Block I/O
테이블 풀 스캔과 인덱스 스캔
테이블 풀 스캔
- 테이블에 존재하는 모든 데이터를 읽어가면서 조건에 맞으면 결과로 추출하고 조건에 맞지 않으면 버리는 방식
- HIGH WATER MARK는 테이블에 데이터가 쓰여졌던 블록 상의 최상위 위치로써 테이블 풀 스캔 시는 HWM까지의 블록에 있는 모든 데이터를 읽어야 하기 때문에 시간이 오래 걸릴 수 있다.
- 테이블 풀 스캔으로 읽은 블록은 재 사용성이 낮다고 보고 메로리 버퍼 캐시에서 금방 제거될 수 있도록 관리한다.(LRU리스트에 끝으로 가서 금방 제거된다.)
- 옵티마이저가 테이블 풀 스캔을 선택하는 경우
- SQL문에 조건이 존재하지 않는 경우
- SQL문의 조건을 기준으로 사용 가능한 인덱스가 없는 경우
- 옵티마이저의 판단으로 테이블 풀 스캔이 유리하다고 판단하는 경우
- 전체 테이블 스캔을 하도록 강제로 힌트를 지정한 경우
인덱스 스캔
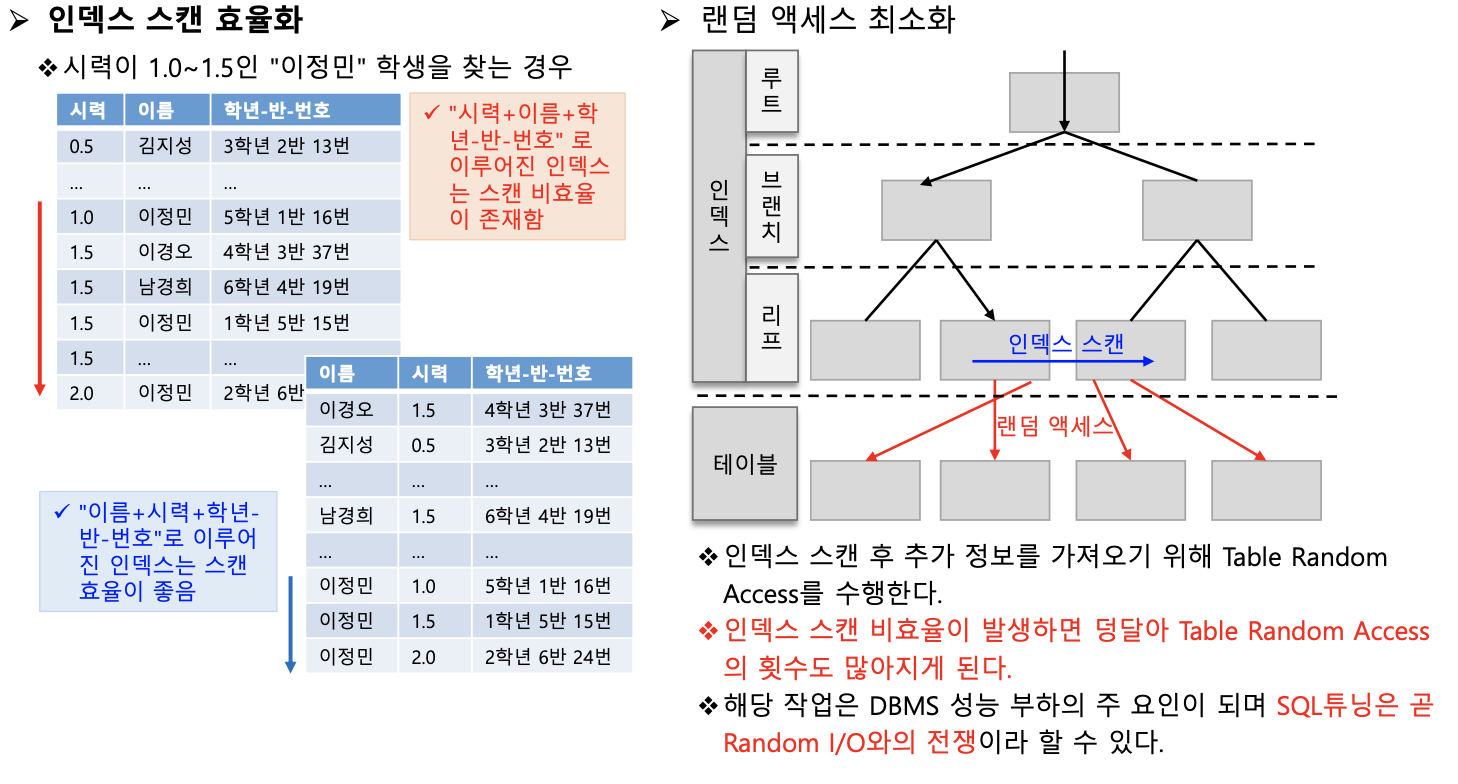
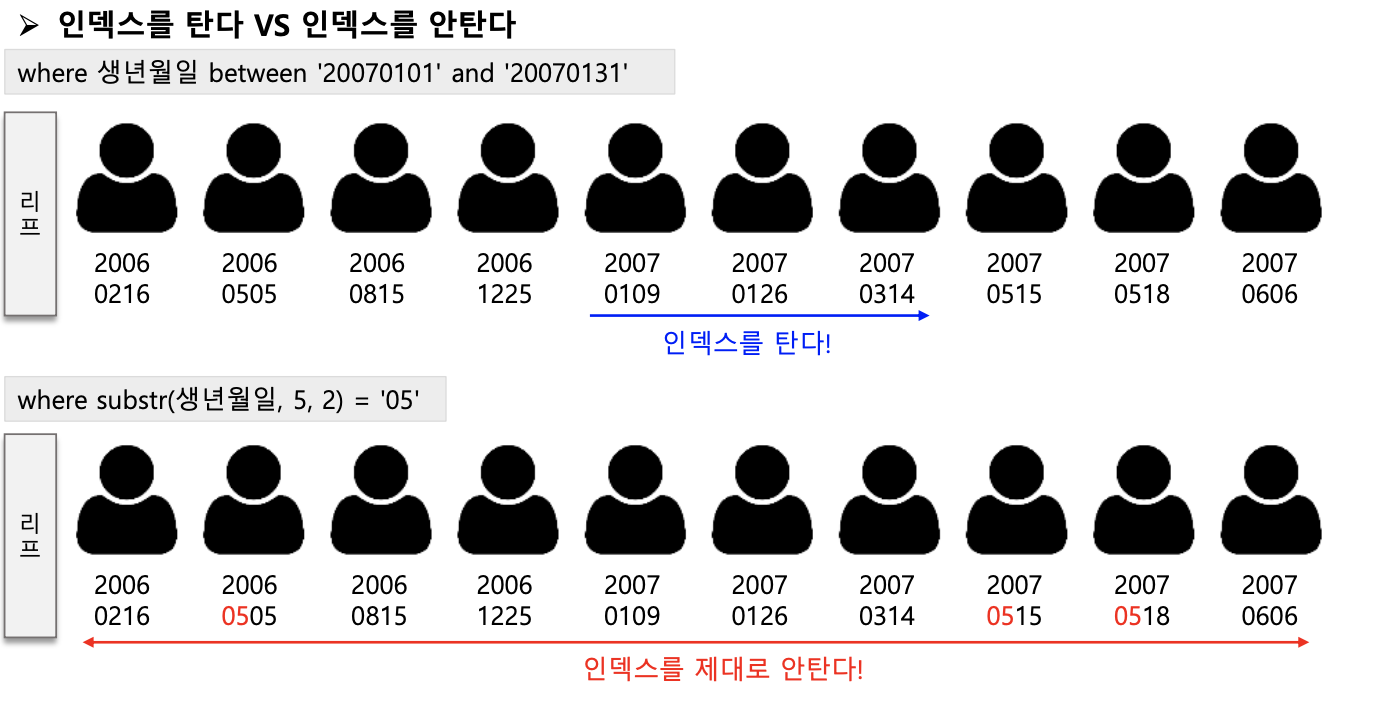
- 인덱스 스캔은 인덱스를 구성하는 컬럼의 값을 기반으로 데이터를 추출하는 액세스 기법
- 인덱스 리프 블록은 인덱스를 구성하는 컬럼과 ROWID로 구성
- 인덱스의 리프 블록을 읽으면 인덱스 구성 칼럼의 값과 ROWID를 알 수 있음
- 즉 인덱스를 읽어서 대상 ROWID를 찾으면 해당 ROWID로 다시 테이블을 찾아 가야함 (Table Random Access발생)
- 하지만 SQL문에서 필요로 하는 컬럼이 모두 인덱스 구성 칼럼이라면 테이블을 찾아갈 필요 없음
- 일반적으로 인덱스 스캔을 통해 데이터를 추출하면 해당 결과는 인덱스의 칼럼의 순서로 정렬된 상태로 반환됨
- 인덱스 스캔으로 읽은 블록은 테이블 풀 스캔에 의해서 읽은 블록에 비해 버퍼 캐시에 더욱 더 오랫동안 남아 있는다.
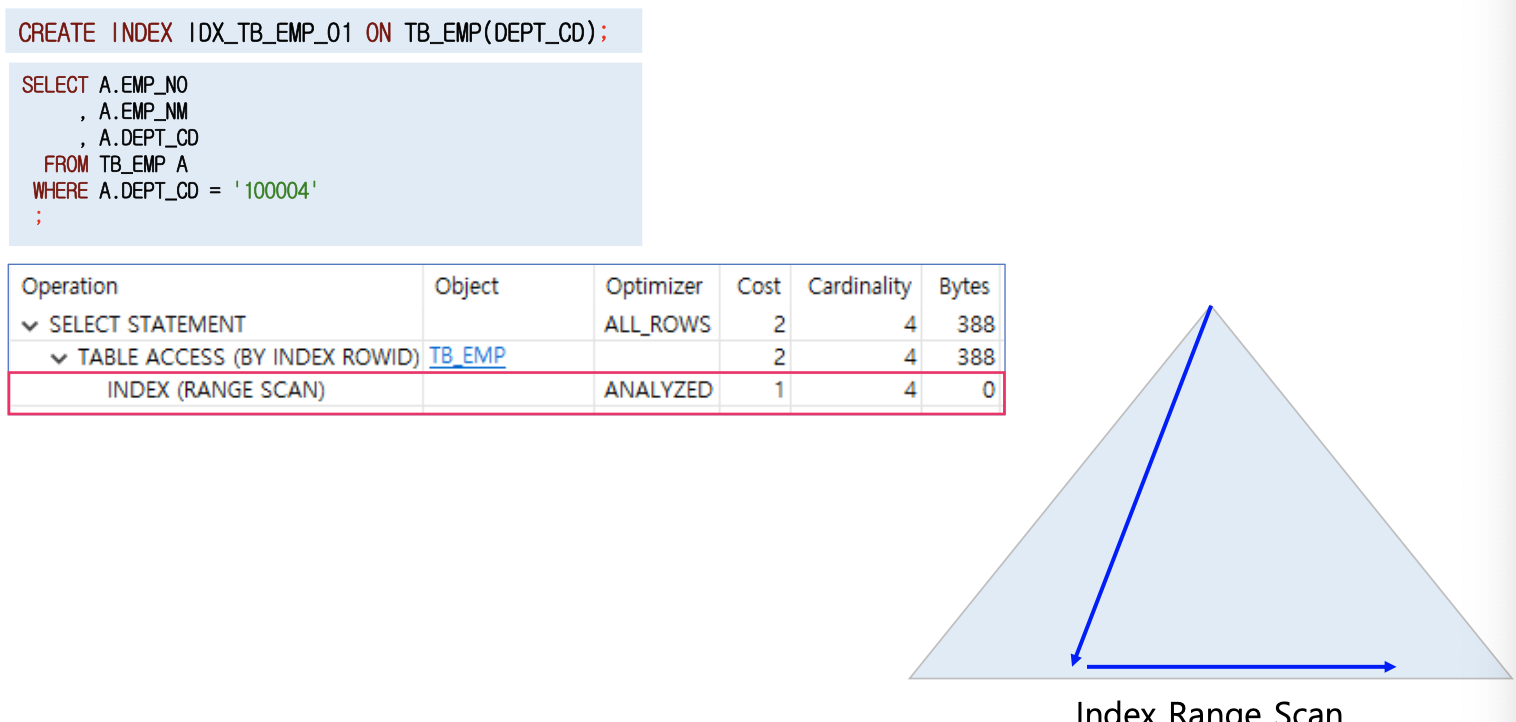
인덱스 범위 스캔
- 인덱스를 이용하여 한건 이상의 데이터를 추출하는 방식
- 인덱스 스캔으로 특정 범위를 스캔하면서 대상 레코드를 하나하나 리턴하는 방식임
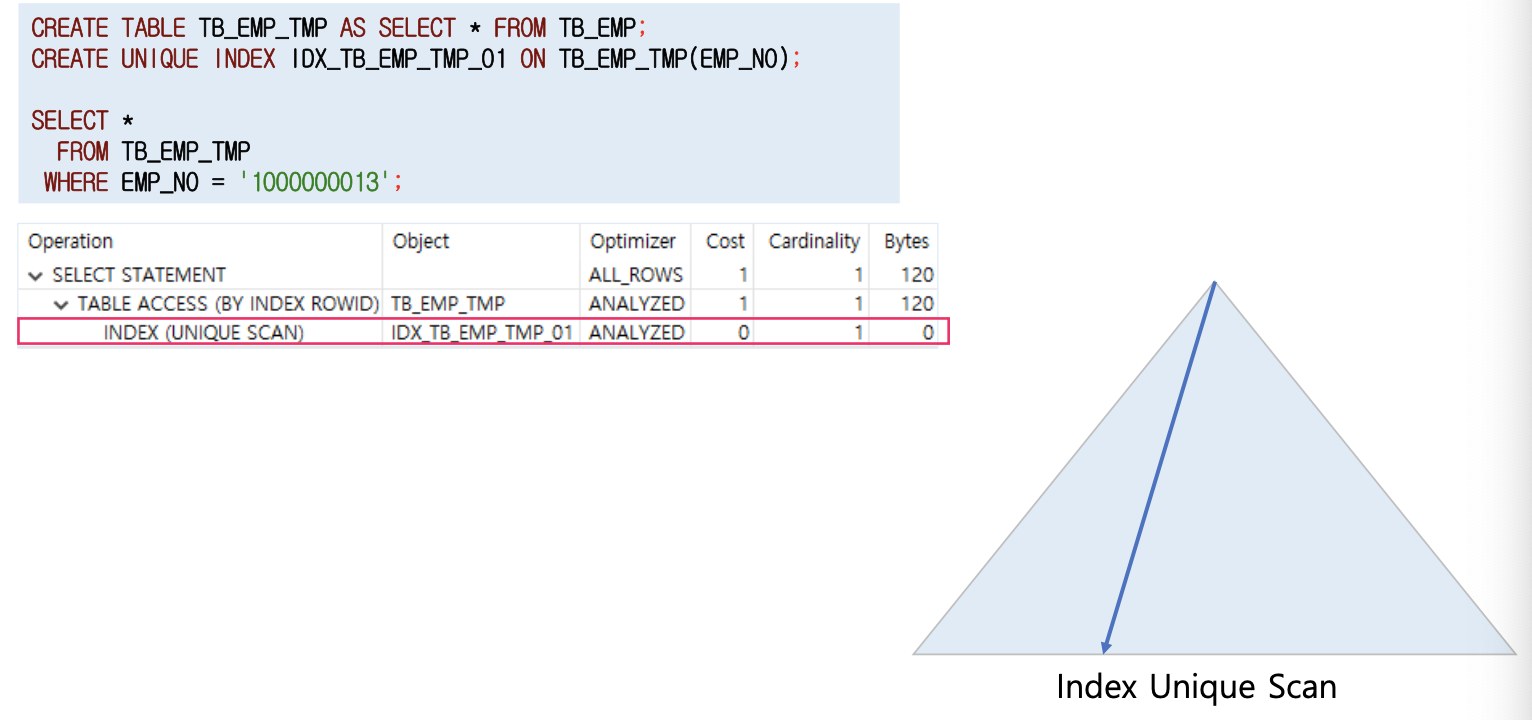
인덱스 유일 스캔
- 인덱스를 사용하여 단 하나의 데이터를 추출하는 방식
- 유일 인덱스는 중복 레코드를 허용하지 않음
- 유일 인덱스는 반드시 '='조건으로 조회 해야 함(그렇게 할 수 밖에 없음)
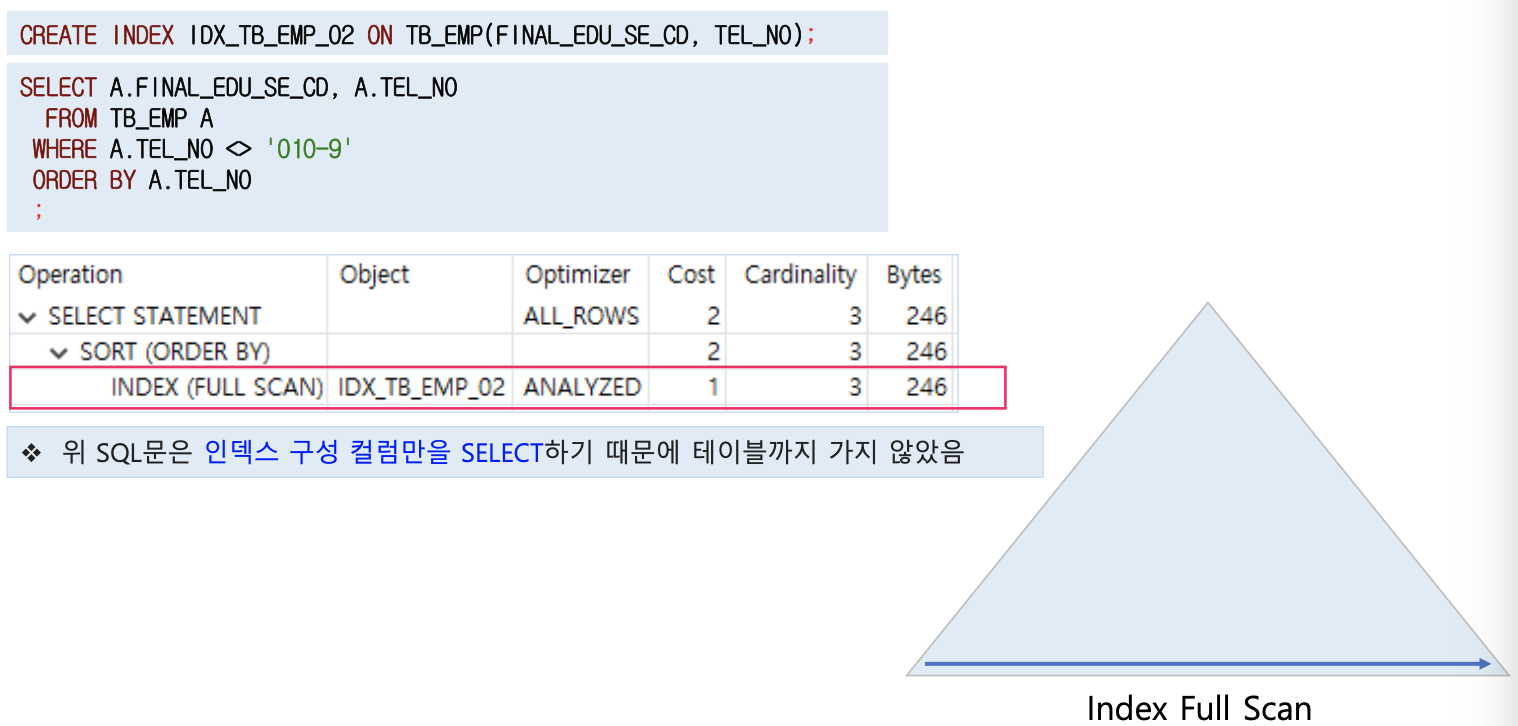
인덱스 전체 스캔
- 인덱스를 처음부터 끝까지 전체를 읽으면서 조건에 맞는 데이터를 추출함
- 데이터를 추출 시 리프 블록에 있는 ROWID로 테이블의 레코드를 찾아가서 조건에 부합하는지 판단하고 조건에 부합되면 해당 행을 리턴 함
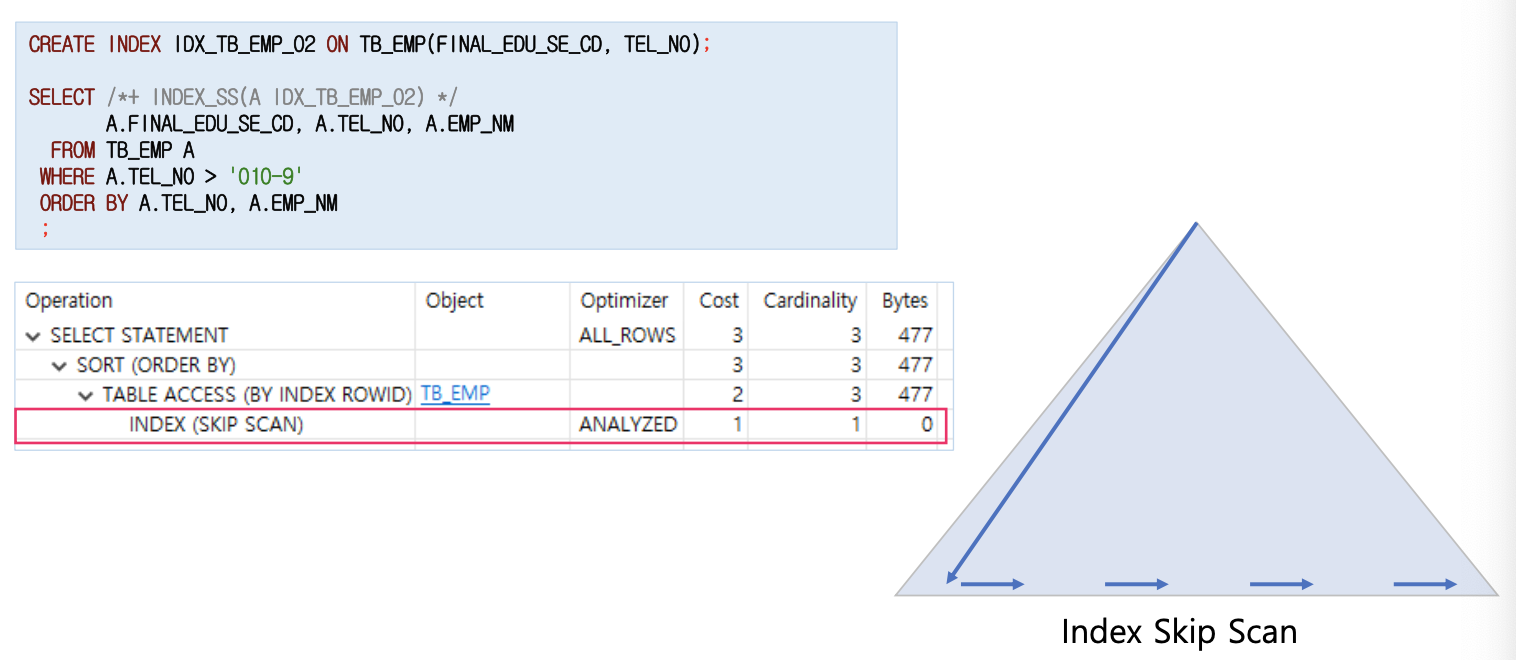
인덱스 스킵 스캔
- 인덱스 선두 컬럼이 조건절에 없어도 인덱스를 활용하는 스캔 방식이다.
- 조건절에 빠진 인덱스 선두 컬럼의 Distinct Value의 개수가 적고, 후행 컬럼의 Distinct Value의 개수가 많을 때 유용
- 루트 또는 브랜치에서 읽은 컬럼 값 정보를 이용해 조건절에 부합하는 레코드를 포함할 가능성이 있는 리프 블록만 엑세스 한다.
인덱스 고속 전체 스캔
- Index Fast Full Scan은 물리적으로 디스크에 저장된 순서대로 인덱스 리프 블록들을 Multi Block I/O 방식으로 읽어 들인다. 또한 병렬 인덱스 스캔도 가능하다.
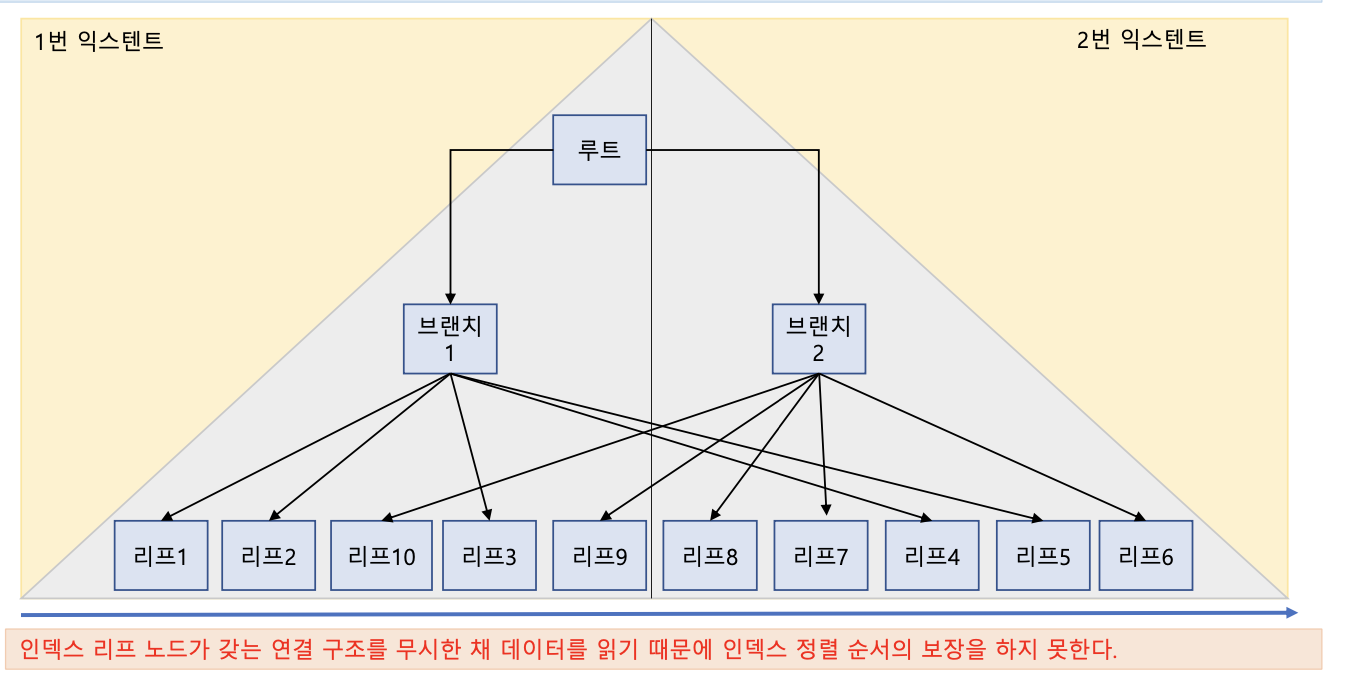
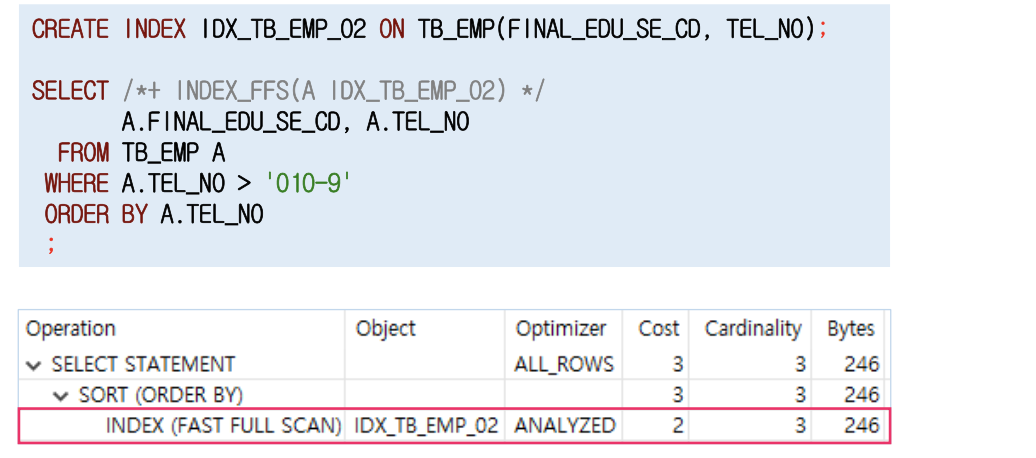
인덱스 역순 범위 스캔
- 인덱스 리프 블록은 Doubly Linked List 방식으로 저장되어 있음
- 즉 이 성질을 이용하여 인덱스를 역순으로(거꾸로) 읽을 수 있음
- 인덱스를 뒤에서부터 앞쪽으로 스캔하기 때문에 내림차순으로 정렬된 결과 집합을 얻을 수 있다. (스캔 순서를 제외하고는 Range Scan과 동일함)
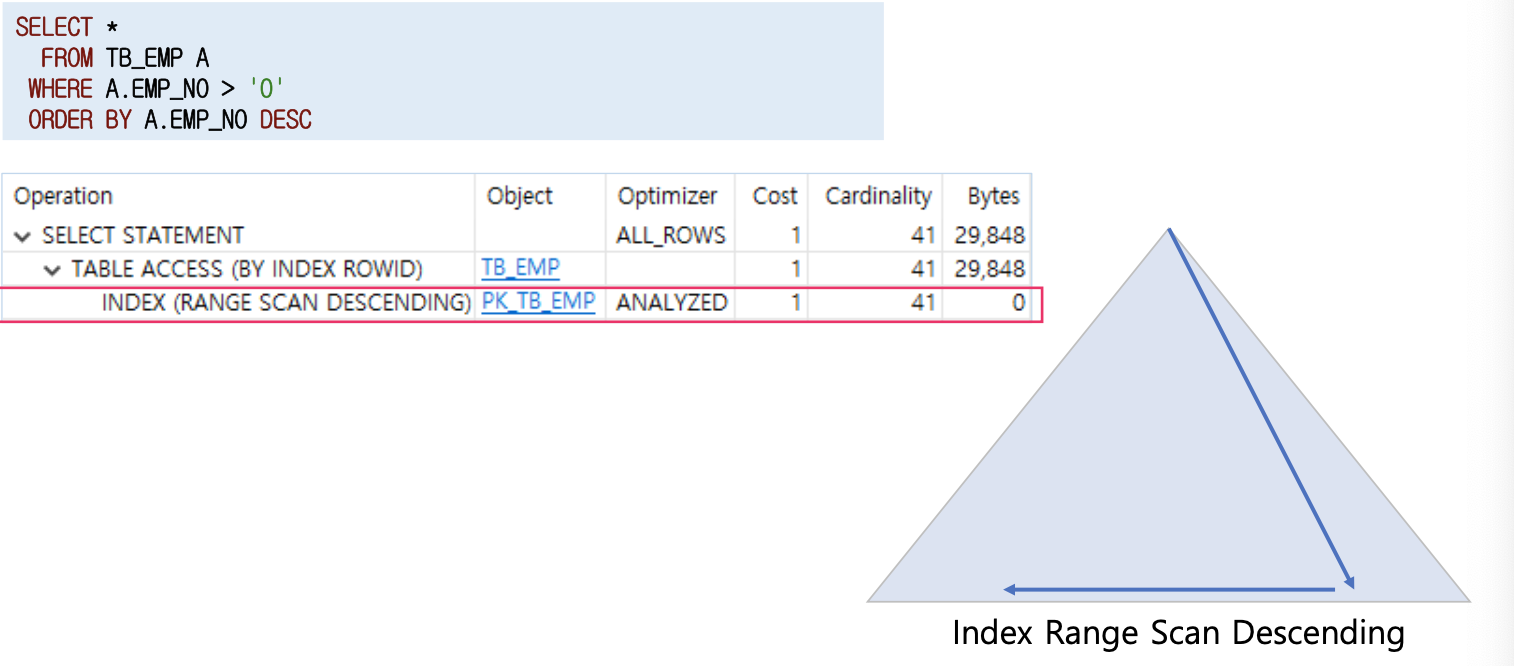
최신정보 조회할 때 유리, 이전주문등
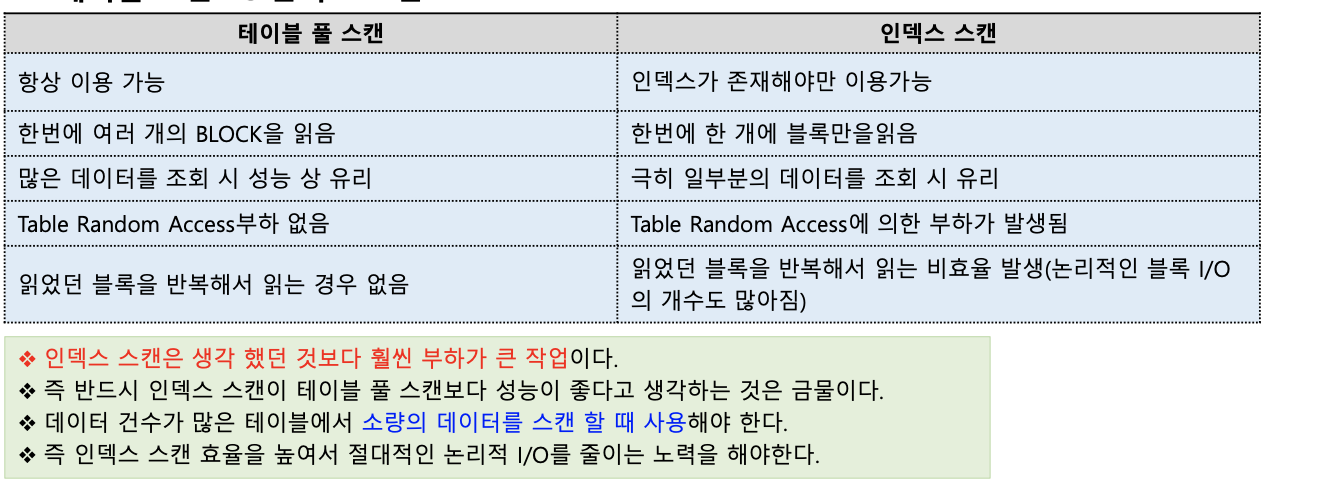
테이블 스캔 vs 인덱스 스캔
'Computer Science > 데이터베이스' 카테고리의 다른 글
| 몽고DB 설치 및 실행 참고자료 (0) | 2023.09.11 |
|---|---|
| 조인 수행 원리 (0) | 2023.06.10 |
| 옵티마이저와 실행계획 (1) | 2023.06.10 |
| SQL 절차형 SQL - Oracle (0) | 2023.06.10 |
| SQL DCL(Data Control Langauge)- Oracle (0) | 2023.06.10 |