
구문과 의미
- 프로그래밍 언어 정의 = 구문 + 의미
- 구문
- 어떤게 생긴 것이 '제대로 생긴 프로그램'인가에 대한 규정
- 가독성
- 쓰기성
- 검증의 수움
- 번역의 쉬움
- 모호성이 없음 ex) if A if B else ~~ else의 대응점이 어딘지 모호, sum-> 변수인지 함수인지
- 의미
- 제대로 생긴 프로그램은 어떤 동작을 하는가에 대한 규정
구문 표기법
- 표준적 구문 표기법
- BNF (Backus-Naur Form)
- EBNF ( Extended BNF)
- CFG (Context-Free Grammar)
- Static semantics
- CFG로 나타낼 수 없는 범위의 구문 규정
- 혹자는 Smemtics의 범주에 포함시기도 함
- Attribute Grammar로 표현
의미 표기법
- Axiomatic Semantics
- 프로그램의 의미를 predicate transformer로 해석
- Denotational Sementics
- 프로그램의 의미를 state transformer로 해석
- state는 machine state를 나타냄
- 의미론은 약간 난해한 분야임
번역 과정
- 분석
- 종합
- 최적화
- 코드 생성
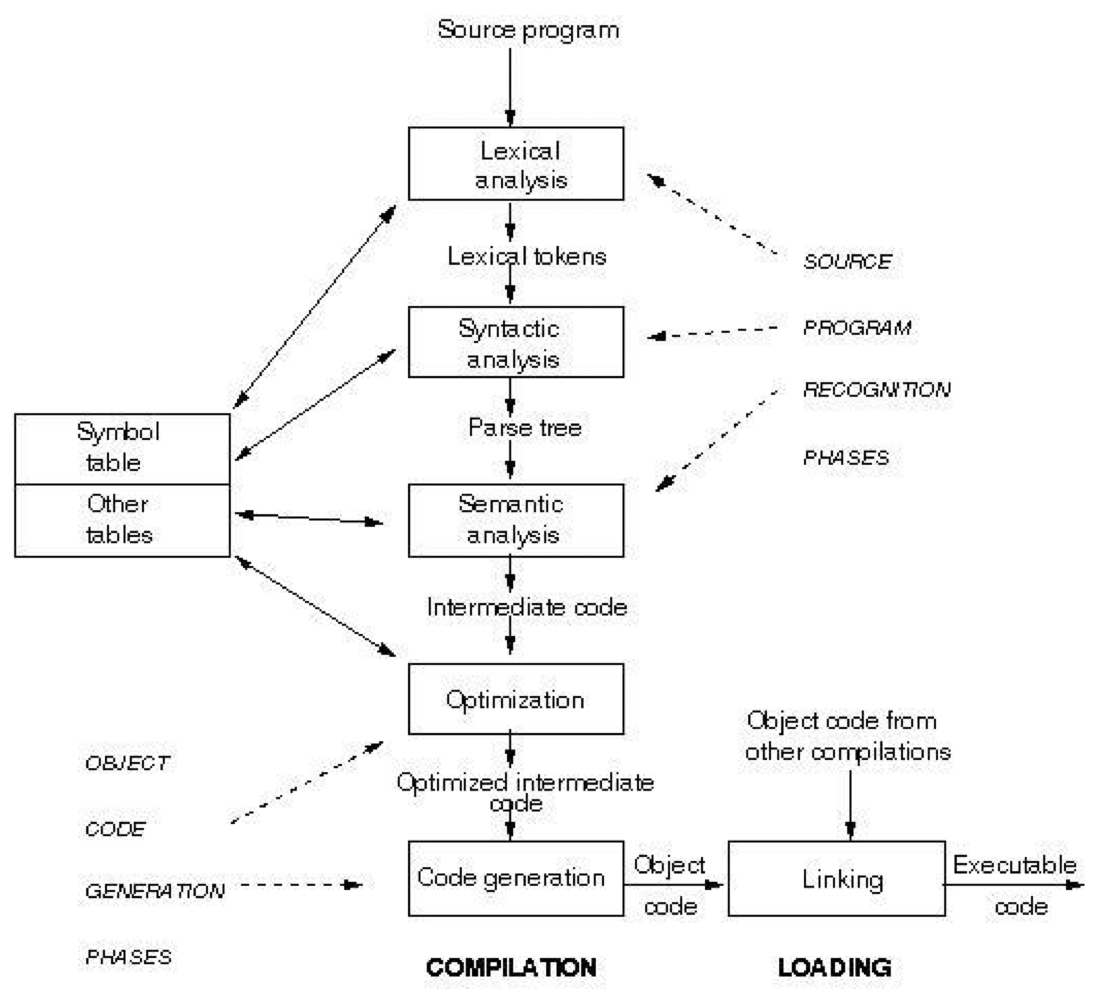
번역 각 단계
- 어휘 분석(lexical analysis; scanning)
- 프로그램을 단어로 나눔
- 주석 제거
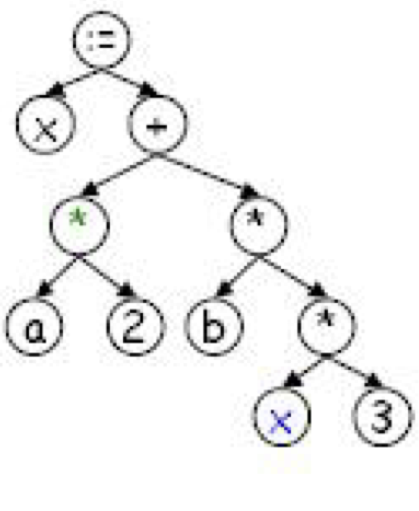
- ex) x:=a*2+b*(x*3) -> id<x> assign id<a> times int<2> plus id<b> times Iparen id<x> times int<3> rparen
- 구문 분석 (Syntax analysis; parsing)
- 구문 구조를 tree로 표현
- parsing tree
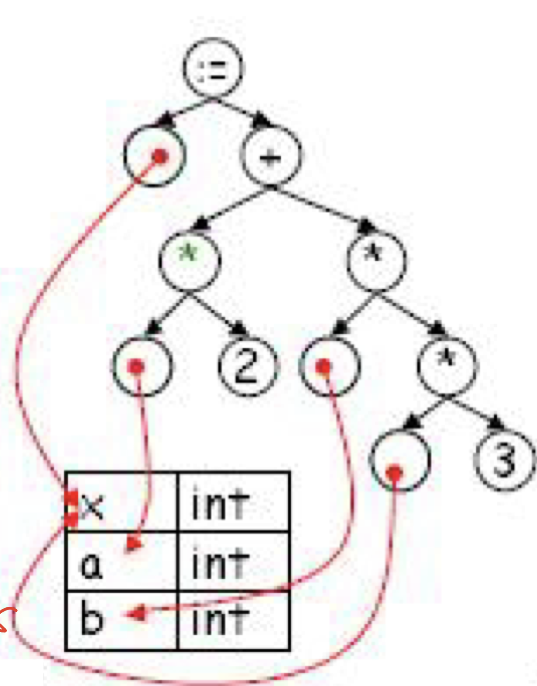
- 의미 분석(Sementic analysis)
- 정적 의미 분석(타입 검사 포함)
- 각 구성요소들이 제대로 사용되었나 검사
- 코드 생성
- tree로부터 수행 가능한 코드 생성

- 최적화
- 트리 형태 또는 코드 형태에서 수행 성능을 개선
- code size, registers, speed, power
Formal Translation Models
- Road Map
- 번역의 모든 단계는 컴파일러 과목 참고
- 여기서는 구문 분석 단계만 간단히 소개
- Formal Model
- BNF, EBNF, CFG의 표현력은 모두 동등함
- BNF로 구문을 표현하는 법 기술
- Implementation
- Parser 작성: BNF에 입각하여 단어들의 나열을 tree로 생성하도록 작성
- parser 생성 도구 : BNF와 Tree 생성 routine을 함께 쓰면 프로그램을 만들어 줌 ex.yacc
BNF (Backus-Naur Form)
구성요소
- Nonterminal (비단말 기호)
- 다른 형태로 치환 가능한 기호(변수)들의 유한 집합
- 꺾은 괄호로 감싸 나타냄
- 예: <sentence> <subject> <predicate> <verb> <article> <noun>
- Terminal (단말 기호)
- 더 이상 치환할 수 없는 기호(상수)들의 유한 집합
- 그냥 쓰거나 따옴표로 감싸서 나타냄
- 예: the, boy, girl, ran, ate, cake, "*"
- Start symbol(시작기호)
- 특별히 지정된 하나의 비단말기호
- 예: <sentence>
- (중요) Rulse (Productions; 생성규칙)
- 각 비단말기호를 어떻게 바꿔 쓸 수 있는가에 대한 유한 개의 규칙(rewriting rulse)
- 예시
- <sentence> ::= <subject> <predicate>
- <subject> ::= <article> <noun>
- <precidate> ::= <verb> <article> <noun>
- <verv> ::= ran | ate
- <article> ::= the
- <noun> ::=boy | girl | cake
- 치환 연산(Replacement Operator)
- 비단말기호를 규칙에 따라 다시 쓰는 것
- 기호 => 로 나타냄
유도(Derivation)
- 유도란?
- 시작기호로부터 치환 연산을 반복하여 적용하는 과정
- 이렇게 만들어진 단말기호 나열을 문장(sentence)이라고 함
- 유도의 예 : 위의 구성요소4번의 예시를 생성규칙으로한 유도가정

기타 내용
- 다음 <sentence>도 유도 가능하다
- <sentence> => *the cake ate the boy
- Syntax does not imply correct semantic
- 다른 표기법
- Rule <A> ::= <B><C>
- 위 BNF 규칙은 CFG에서 다음과 같이 표기하기로 함
- A->BC
몇 가지 용어들
- Sentence(문장)
- 시작기호로부터 유도된 단말기호의 나열
- Sematial forms(문장형태)
- 장차 문장이 될 수도 있는 형태(이미 문장일 수도 있음)
- Language(언어)
- 문법의 규칙에 따라 유도 가능한 모든 문장들의 집합
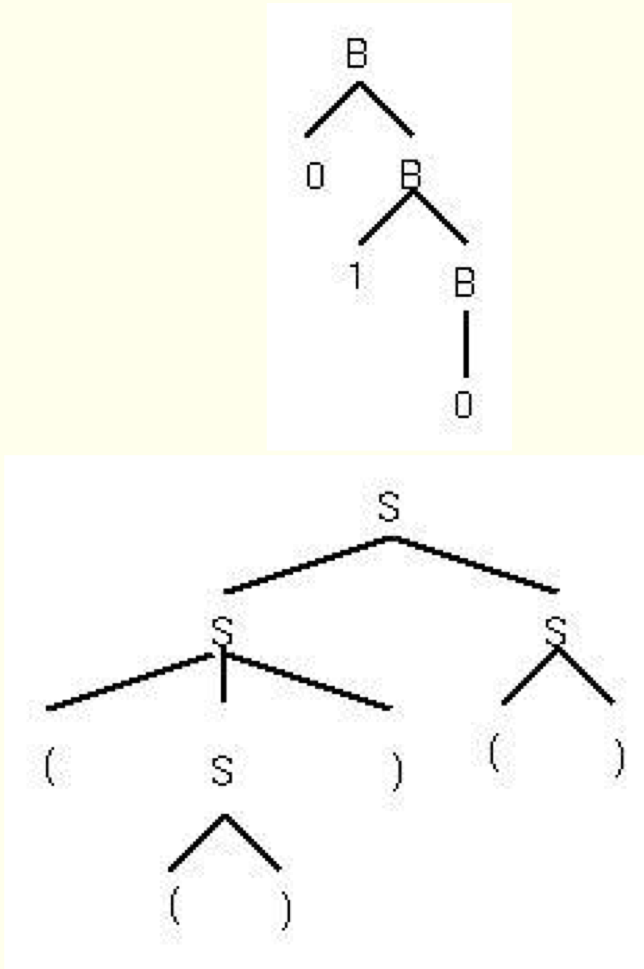
Parse Tree(유도트리,derivation tree)
- 파스트리
- 유도 고정을 나타낸 트리
- 유도 트리라고도 함
- 유도트리의 예
- Grammar: B -> 0B | 1B | 0 | 1
- Derivation: B => 0b => 01b => 010
- 유일한 표현(?)
- S -> SS | (S) | ()
- S => SS => (S)S => (())S => (())()
- S => SS => S() =>(S)() => (())()
Ambiguity
- 모호성
- 어떤 문법에서는 같은 문자열에 대해 두 개 이상의 파스트리가 얻어질 수 있음
- 이러한 문법을 모호한 문법이라고 함
- 모호한 문법의 예
- S -> SS | (S) | ()
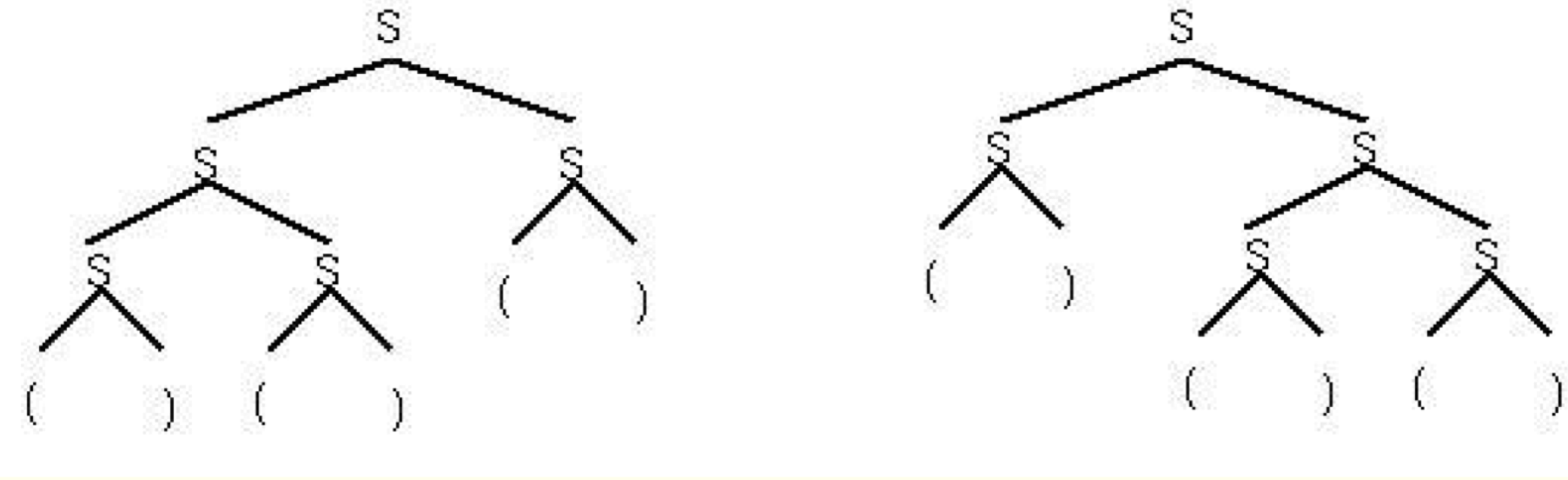
왜 모호성이 문제가 되는가?
- 다음 식의 값은? 2*3+4*5
- 26
- 70
- 50
- 구문은 어느 정도의 의미를 내포하고 있다.
- 구문이 모호하다면 다른 의미를 내포할 가능성이 있음
- ALGOL 시대에는 BNF로 의미를 표현할 수 있다고 생각했었음
- 위와 같은 수식을 위한 BNF?
- E -> E+E
- E -> E*E
모호한 문법에 대한 대처법
- 문법 변경
- 모호한 뭄법 G를 모호하지 않은 문법 G'으로 변경하되 L(G) = L(G')이 되도록 한다.
- 파서 변경
- 파서에서 특정 트리를 선택하도록 한다
- 컴파일러을 만들 때 어떤 작업을 먼저할지 선택해준다
EBNF
- EBNF = BNF + 메타기호 세가지 더
- BNF의 메타기호 ::= , |, <>
- 그렇지만 EBNF의 표현력은 BNF의 표현력과 같음
- 조금 더 편리함
- EBNF의 메타기호
- 생략가능, 조건문에서 사용됨: [...]
- <number> ::= <digits> [.<digits>]
- or : (...|...|...)
- <signed number> ::= (+|-) <number>
- 반복: {...}*
- <identifier> ::= <letter> { <letter> | <digit> }*
- 생략가능, 조건문에서 사용됨: [...]
EBNF와 BNF의 표현력은 같다. 다만 EBNF가 간결하고 편할 뿐

Syntax Chart
- Syntax Chart(Diagram)
- 구문규칙을 그림으로 표현
- 좌측 비단말기호는 가장 처음 화살표의 시작 부분에
- 단말기호를 동그라미로
- 비단말기호를 네모로
- 나열은 화살표로
- 예: <expr> ::= <term> { (+|-)<term>}*
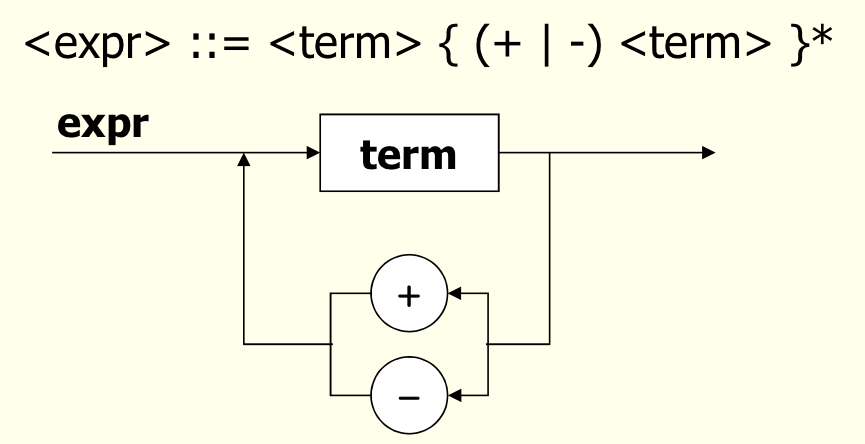
More Realistic Syntax Chart
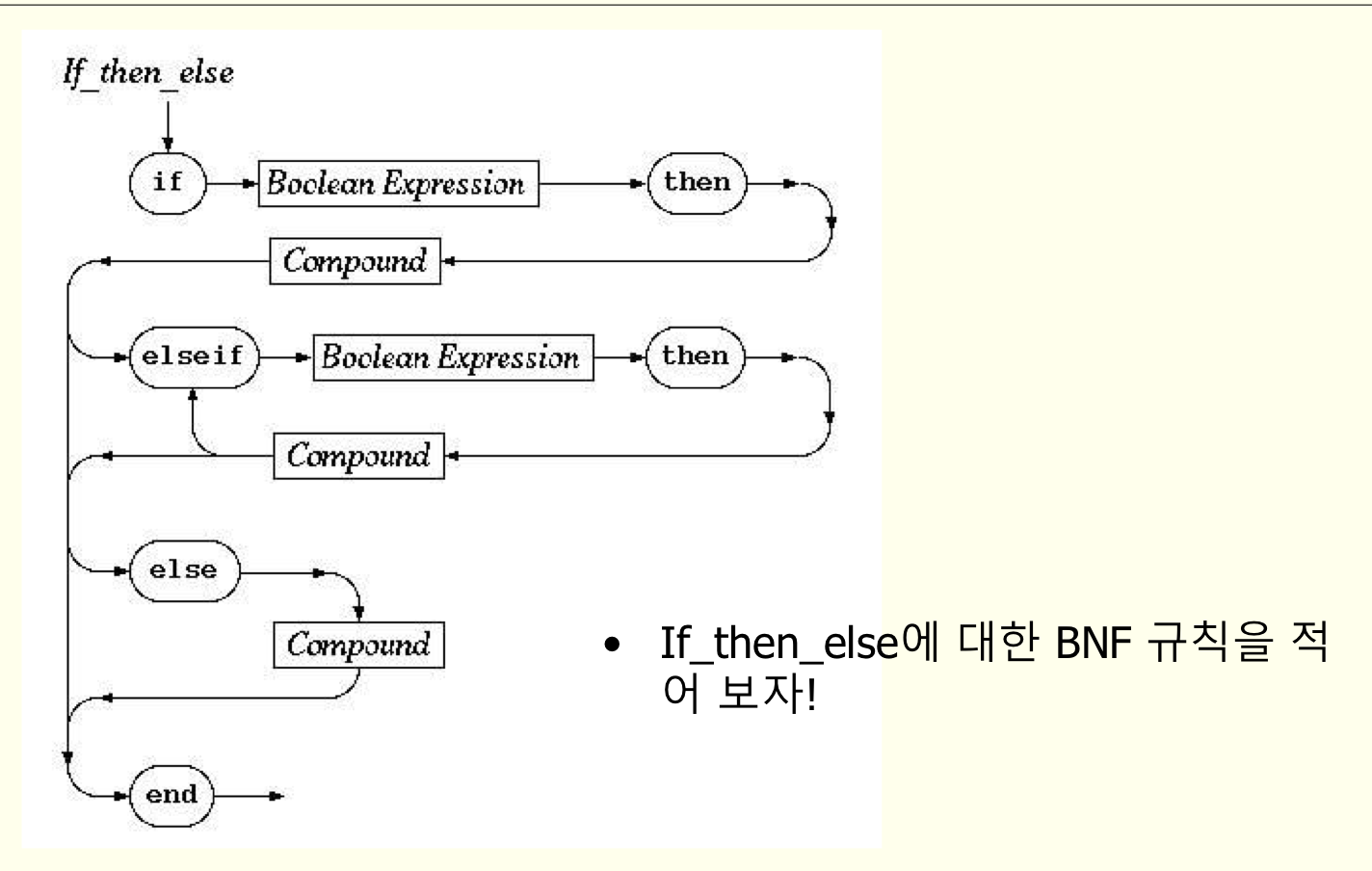
BNF
<if문> ::= if <논리식> then <문장> else <문장> | if <논리식> then <문장>
EBNF
<if문> ::= if <논리식> then <문장> [ else <문장> ]
Finite State Automata
- Grammar and Automata
- 문법은 언어 생성기
- 오토마타는 언어 인식기
- Finite Automation
- 유한 개의 상태로 문자열을 인식하는 자동 기계
- Finite State Machine의 일종
- 초기상태(initioal state)로부터 시작하여 입력 기로를 보고 상태전이
- 최종상태(final state)에 도달하면 그때까지 읽은 입력 기호 문자열 인식
- FA M이 인식하는 언어 L(M)={w |δ(A,w) =C}, 여기서 A는 초기상태, C는 최종상태 중 하나
- FA= {Q,∑,δ,q0,F}
Q= state의 유한집합
∑=유한 input character
δ= QX∑ ->Q
q0= 초기state (Q에 포함됨)
F= 유한 states의 집합 (Q의 부분집합)
- FA의 예
- 홀수개의 1을 인식하는 오토마타
- 입력 100101이 주어졌을때
move(A,100101)
= move(B,00101)
= move(B,0101)
= move(B,101)
= move(A,01)
= move(A,1)
=B - B가 종결상태이므로 홀수개임으로 인식함
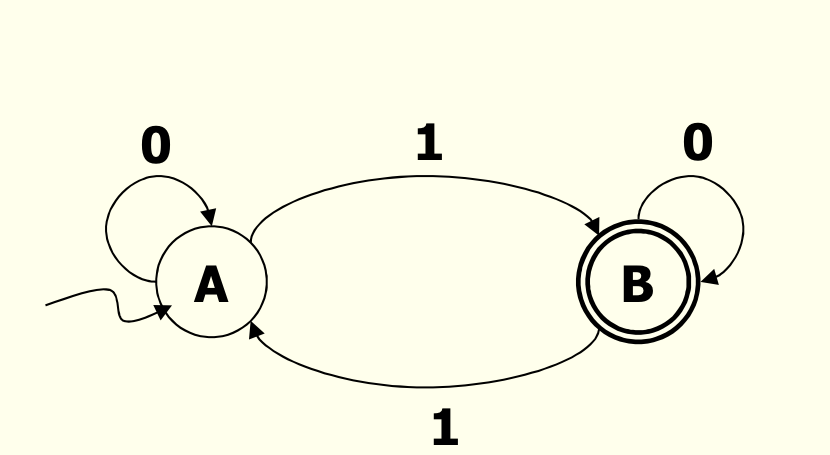
DFA와 NFA
- DFA (deterministic finite automata)
- 어떤 상태에서 한 입력 기호를 보고 갈 수 있는 상태가 단 하나
- NFA (nondeterministic finite automata)
- 어떤 상태에서 한 입력 기호를 보고 갈 수 있는 상태가 여러 개 일 수 있음
- 모든 DFA는 NFA의 일종
- 여러 가능성 중에서 하나라도 최종 상태에 도달하면 인식
- NFA의 예
- move(A,01) = move(B,1)=C
- move(A,01) =move(B,1)=D (인식)
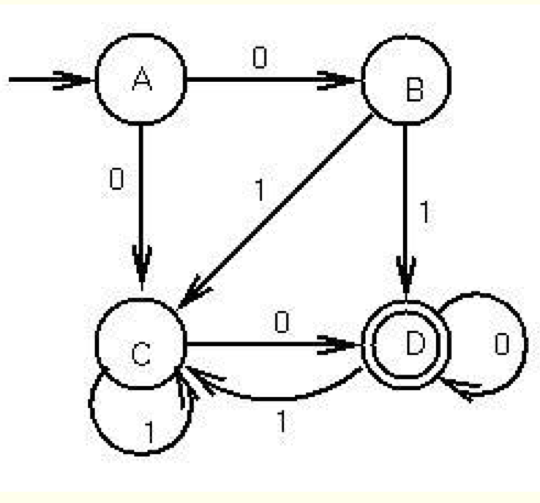
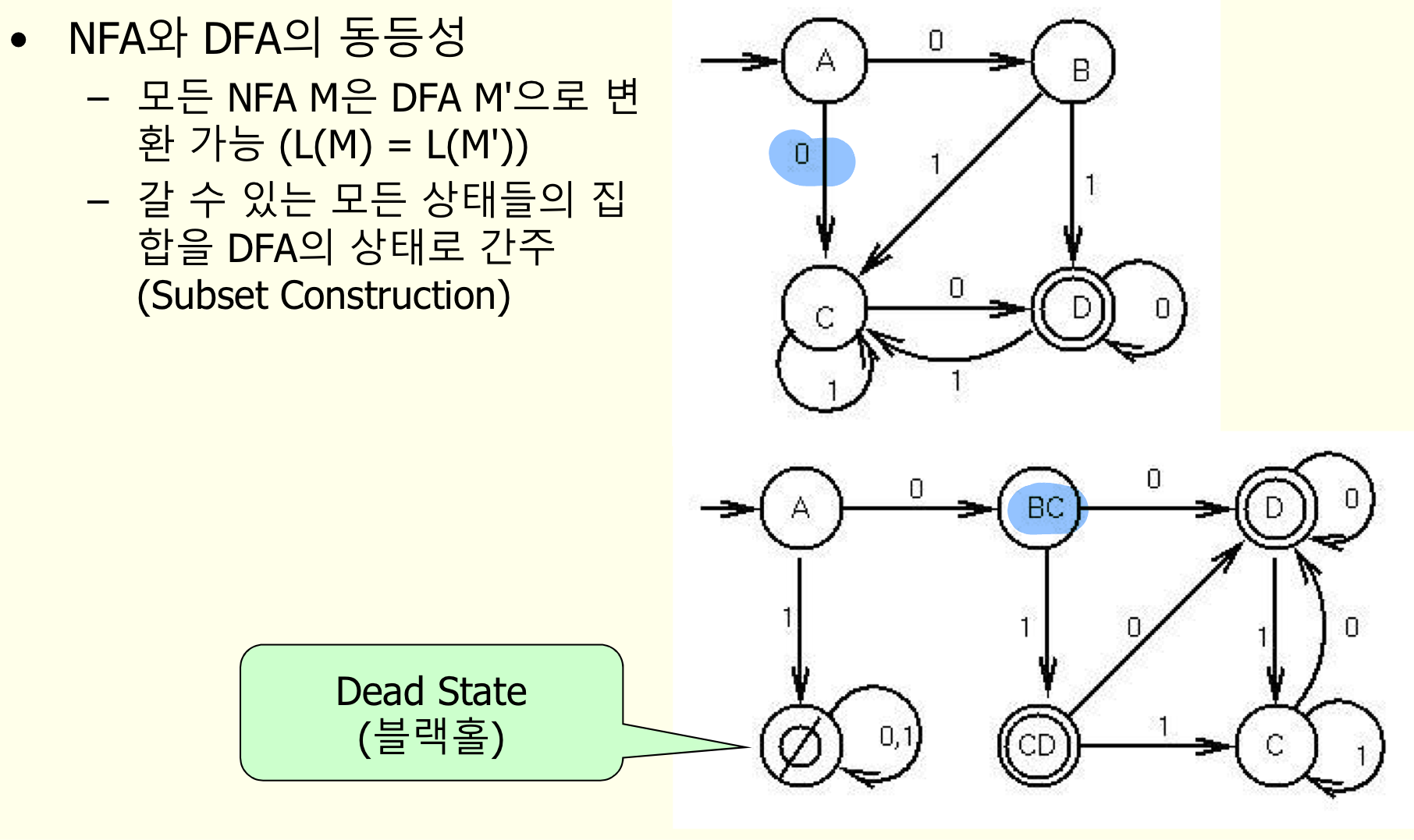
NFA에서 DFA로의 변환
정규문법(Regular Grammar)
- 다음과 같은 형태의 생성 규칙으로만 이루어진 문법
<nonterminal> ::= <terminal><nonterminal>|<terminal> - 우변의 특정 위치(우측끝)에만 비단말기호가 올 수 있으며, 개수도 하나만 허용됨
- 정규문법의 예)
A -> 0A | 1A | 0 - Left Linear, Right Linear
- 어떤 정규문법에서는 우변의 좌측 끝에만 비단말기호가 올 수 있다고 정의하고 있음(left linear문법)
- 위 예는 right linear 문법
정규식(Regular Expression)
- 정규식의 정의
- 단말기호는 정규식
- a와 b가 정규식이면 (a|b),(ab),(a*)도 정규식
- 공문자열ε ,공집합∅도 정규식
- 정규식의 장점
- 정규언어를 간단한 식으로 표현할 수 있음
- 정규식의 예
- 2로 나누어 질 수 있는 이진 문자열
(0|1)*0 - 01을 포함한 이진 문자열
(0|1)*01(0|1)*
- 2로 나누어 질 수 있는 이진 문자열
정규식(Regular Expression)
- 정규언어 (Regular Language)
- 일반적으로 프로그래밍 언어 어휘의 패턴을 나타내기에 충분한 언어
- 정규식(Regular Expression)
- 어휘의 패턴을 나타내는 방법
- FA(Finite Automata)
- 어휘를 인식하기 위한 기계 -> 어휘 분석기
- 정규식 -> NFA -> DFA
- FA에서 공집합, 공문자열표현
Grammar and Automata
- 문법(grammar)
- 언어 L(G)에 대한 설계도 G
- 문장(문자열) 생성기
- 오토마타(automata)
- 문자열 인식기
- 패턴(예 정규식으로 나타낸 패턴) 인식기
- a(a|b)*b를 인식하는 프로그램을 작성하라
- ab -> Yes
- abba -> No
- 수식 계산기를 작성하라
- infix ->postfix 번역기를 작성하라
- 12+(24+3)
- 12 24 3 ++
- 위와 같은 문제들을 어떻게 해결 할 것인가?
- 문자열 인식기 작성
- 여기에 필요한 작업 추가
- 수식 계산기의 경우 계산 작업
- inpix->postfix 변역기의 경우 출력 작업
Pushdown Automata
- PDA = FA + Stack
- 여기서 stack은 pushdown list 라고도 함
- 결과적으로 상태가 무한하게 늘어나게 됨
- PDA 동장
- 입력기호(current input symbol)와 스택기호(stack top)를 읽음
- 상태전이 및 스택변경(0개이상의 스택기호 푸시)
- 입력문자열을 모두 읽고 스택이 비어 있으면 입력 문자열 인식 (또는 입력문자열을 모두 읽고 최종 상태에 도달하면 입력문자열 인식)
- PDA가 FA보다 강력한 점
- 입력 문자 개수를 셀 수 있음 (a^n b^n)
PDA 예

PDA와 유도
- PDA가 인식하는 언어 = ? = BNF가 나나내는 언어
- PDA는 좌측 유도를 흉내낼 수 있다.
- 초기상태: Stack Top에 시작기호가 들어 있음
- 상태 전이
- stack top이 terminal이고 현재 입력기호롸 같으면, stack top을 pop하고 혐재 입력을 하나 읽는다.
- stack top이 nonterminal X 이면 , 생성규칙 X ->a 에 대하여 a를 X대신 stack top에 넣는다. 입력 문자는 읽지 않는다.
- 주의
- 위 PDA는 비결정적임(임의의 nonterminal X에 대해 X가 좌변인 생성규칙은 많을 수 있음)
- 위 PDA는 스택을 비울 때 입력 문자열을 인식
NDPDA != DPDA
- PDA의 인식능력차이
- Nondeterministic PDA와 Deterministic PDA가 인식하는 언어는 다르다.
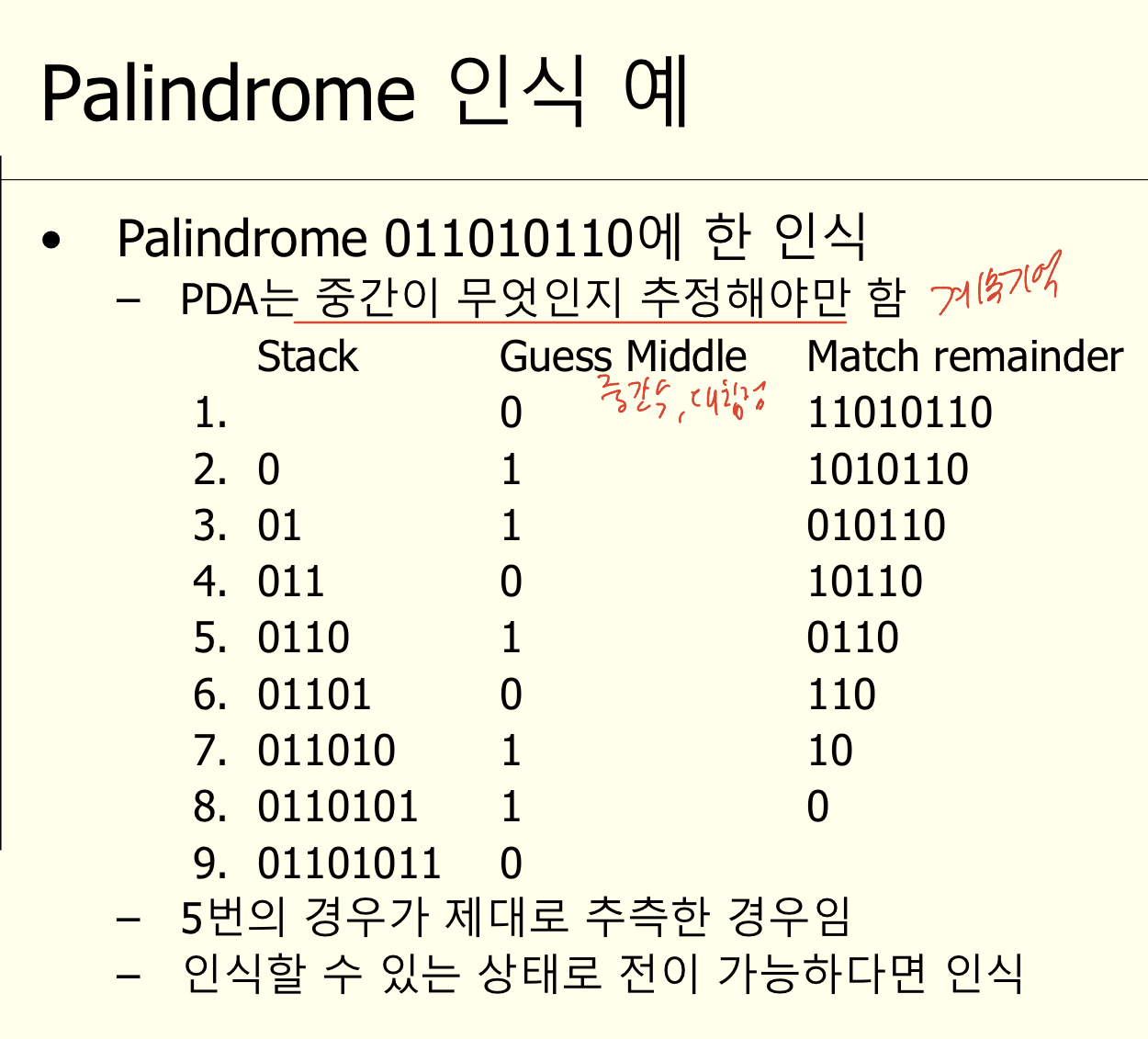
- Palindrome 예시
- Deterministic PDA로 인식가능한 Palindrome:
S -> 0S0 | 1S1 | 2
1. 0과 1은 읽을 때마다 스택에 넣음
2. 2를 읽으면 다른 상태로 이동
3. 스태그이 기호를 빼내며 입력과 같은가 확인 - Nondeterministic PDA로 인식 가능한 Palindrome
S -> 0S0 | 1S1 | 0 | 1
이 경우에는 중간에 0과 1 중에 무엇이 올 지 알 수 없음 - 따라서 중간 문자를 예측해야함
- Deterministic PDA로 인식가능한 Palindrome:
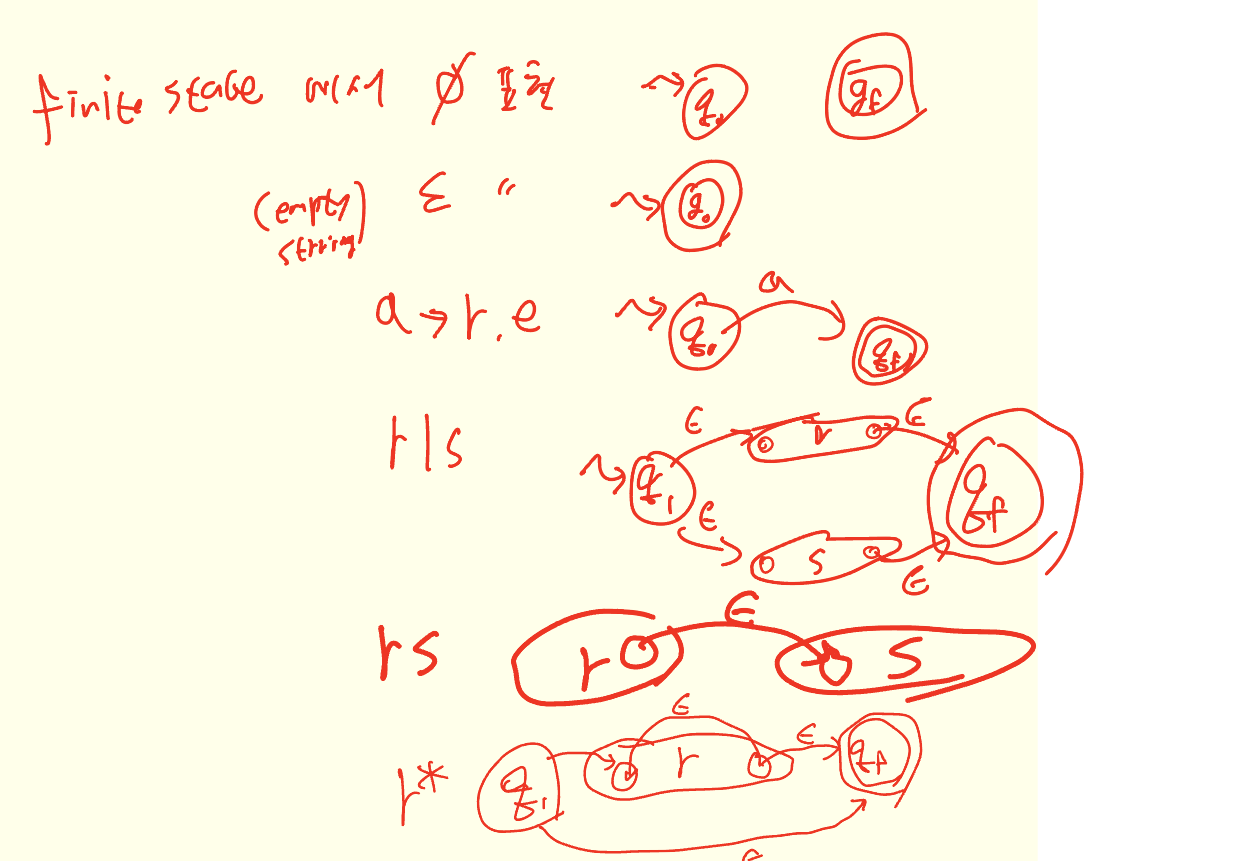
Recursive Desent Parsing
- 순서 하강 파서
- 간단한 하향식 구문 분석 방법
- 문법(BNF 또는 CFG)과 파서의 구조가 동일
- nonteminal에 해당하는 재쥐적 프러시저들로 구성됨
- 순환하강 파서 구성 방법
- 각 생성규칙에 대해 생성규칙의 우변을 따라하는 프로시저 구성
- nonterminal -> 프로시저 호출
- terminal -> lookahead와 일치하는가 검사하고 일치하면 skip 그렇지 않으면 신택스 에러



'Computer Science > 프로그래밍언어론' 카테고리의 다른 글
| Chapter5-2 Structured Data Types (0) | 2023.06.12 |
|---|---|
| Chapter5-1 Elementary Date Types (0) | 2023.04.20 |
| Chapter4 Modeling Language Properties (0) | 2023.04.20 |
| Chapter 2 Impact of Machine Architectures (0) | 2023.04.18 |
| Chapter1 Language Design Issues (0) | 2023.04.18 |